

OmniGen AI is unique because you can guide it almost like you would a person. Instead of needing special tools or technical steps, you just tell it what you want in simple instructions, and it gets it done. For example:
- “Add a sunset in the background of this picture.”
- “Make this character look like they’re in a winter forest.”
- “Combine these two images into one cool mashup.”
It understands your requests and works its magic without needing you to do any complicated work. It’s like having a super-talented digital artist who listens and creates exactly what you envision—making it easy and fun to create truly unique and amazing images.
In image generation, OmniGen uses a kind of mental map to understand how different things are related. For example, it might connect "dog" to "fur," "tail," and "park," so the computer knows what to include when generating a picture of a dog in a park. It helps the computer "think" about how to combine ideas into a realistic image.
Ready to see what you can create? Let's jump in!
How to run OmniGen in ComfyUI
Installation guide
Verified to work on ThinkDiffusion Build: Dec 5, 2024
ComfyUI v0.3.7 only which is compatible to OmniGen,
just select the previous release of Comfy similar to that date.
Why do we specify the build date? ComfyUI and custom node versions that are part of this workflow that are updated after this date may change the behavior or outputs of the workflow.
Custom Node
If there are red nodes in the workflow, it means that the workflow lacks the certain required nodes. Install the custom nodes in order for the workflow to work.
- Go to ComfyUI Manager > Click Install Missing Custom Nodes
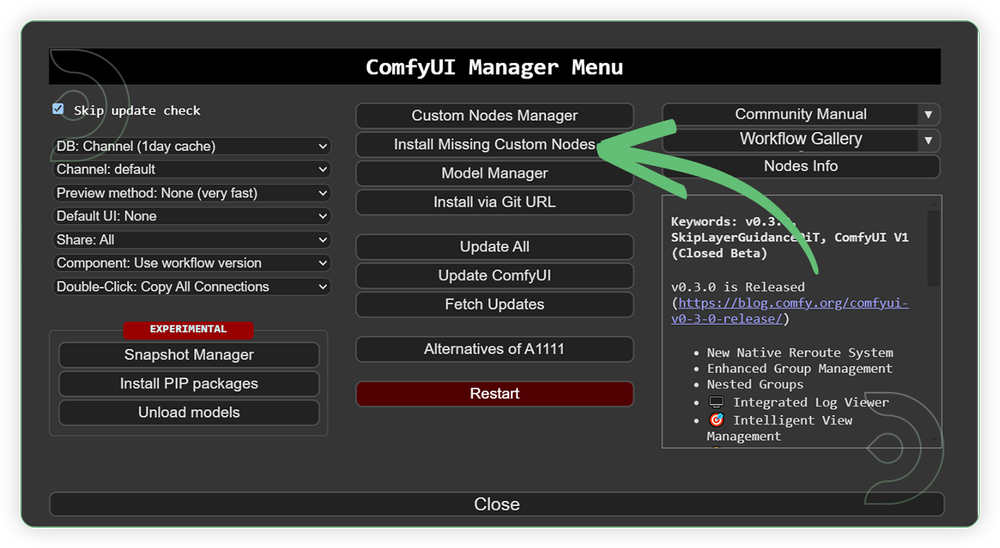
- Check the list below if there's a list of custom nodes that needs to be installed and click the install.
Models
Download the OmniGen model by copying the path below and upload directly to ThinkDiffusion by navigating to /models/LLM/OmniGen-v1/ and using the Upload button and pasting the url.
You can also manually download the OmniGen model from https://huggingface.co/Shitao/OmniGen-v1/resolve/main/model.safetensors?download=true.
| Model Name | Model Link Address | ThinkDiffusion Upload Path |
|---|---|---|
| model.safetensors | …comfyui/models/LLM/OmniGen-v1 |
Step-by-step guide for OmniGen in ComfyUI
| Steps | Default Node to Follow |
|---|---|
| 1. Load an Image | 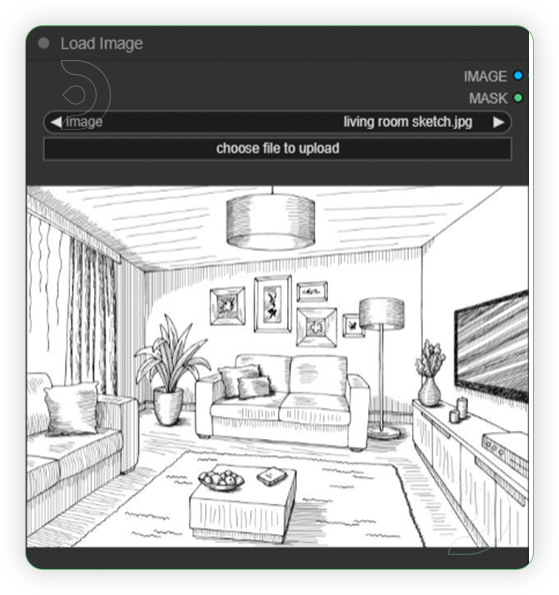 |
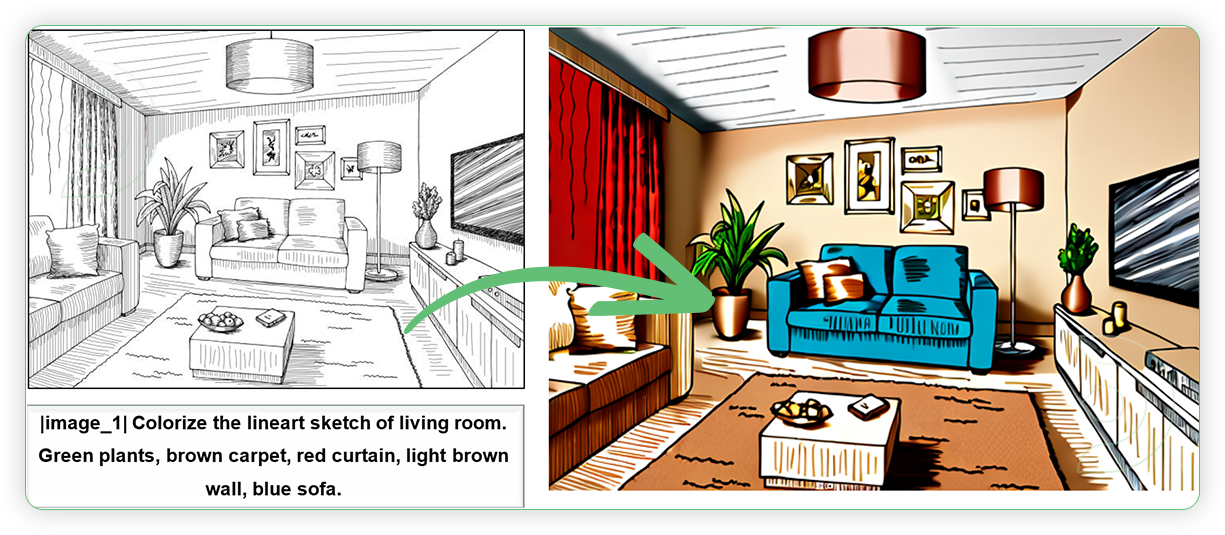
| 2. Write a Prompt When writing the prompt, there is a standard format of prompt. It must include placeholder image_i represents the position of the i-th image. Should have vertical bar before and after of placeholder word. Example: |image_1| Colorize the lineart sketch of living room into a realistic photo. Green plants, brown carpet, red curtain, light brown ceiling, blue sofa, light brown wall |
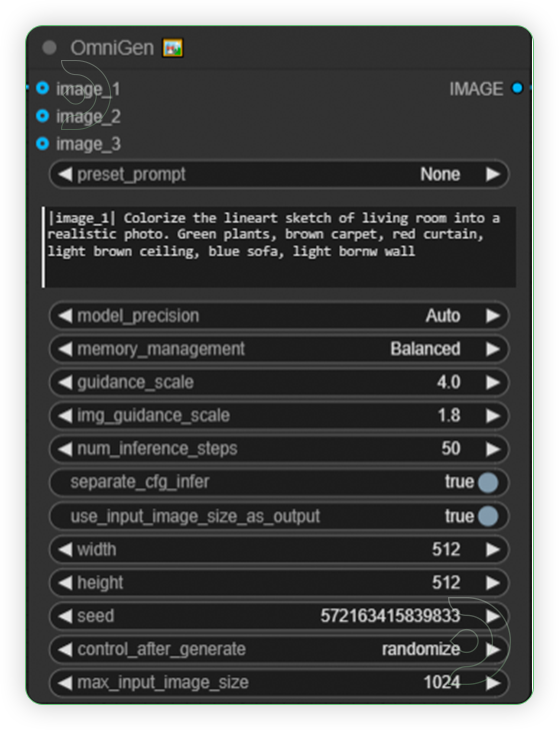 |
| 3. Run the Generation | |
| 4. Check the Generated Image |  |
| 5. Reprompt (Optional) There is chance that you need to reprompt while doin minor changes in OmniGen in order to achieve the right result. |
Limitations of OmniGen
- OmniGen is sensitive to text prompts. Typically, detailed text descriptions result in higher-quality images.
- The current model’s text rendering capabilities are limited; it can handle short text segments but fails to accurately generate longer texts.
- The number of input images during training is limited to a maximum of three, preventing the model from handling long image sequences.
- The generated images may contain erroneous details, especially small and delicate parts.
- Facial features occasionally do not fully align. OmniGen also sometimes generates incorrect depictions of hands.
Examples
Text to Image

Computer Vision


Subject-Driven
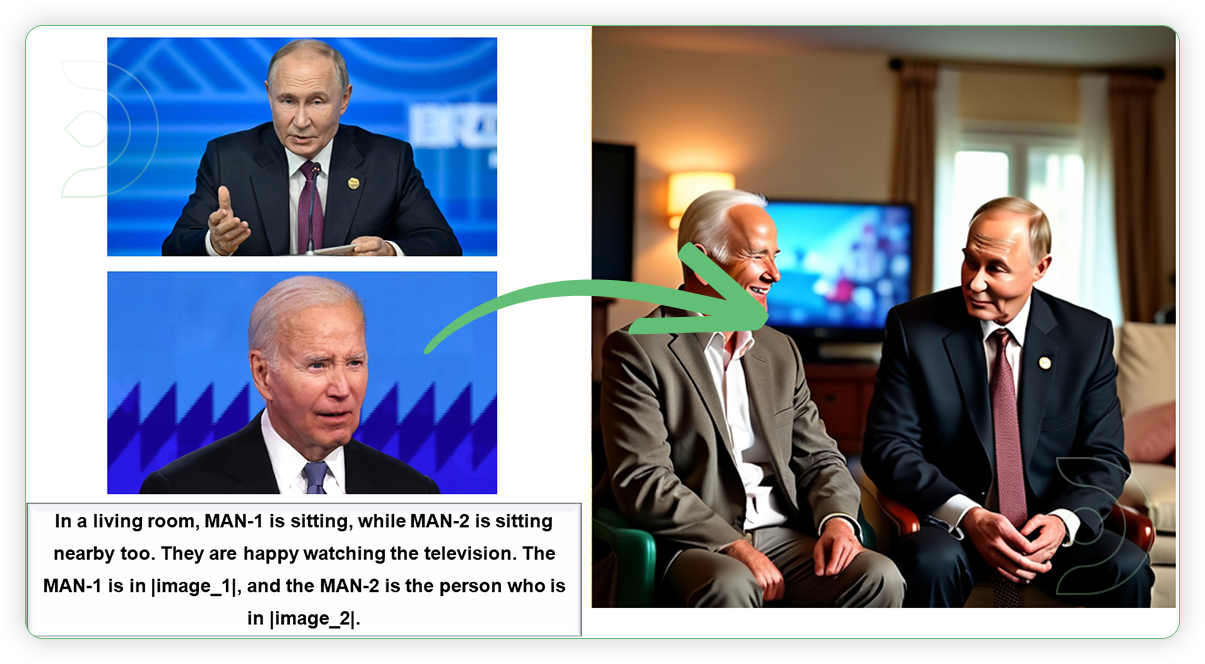

Mixed Modal


Image Editing


If you’re having issues with installation or slow hardware, you can try any of these workflows on a more powerful GPU in your browser with ThinkDiffusion.
If you enjoy ComfyUI and you want to test out creating awesome animations, then feel free to check out this AnimateDiff tutorial here. And have fun out there with your noodles!
Member discussion