


In early August 2024, a new player in the ever-changing world of generative art, FLUX AI by Black Forest Labs, bursted onto the scene. Official assessments have shown that the open-source text-to-image suite FLUX performs better than many of the top models in the field. It has already become a useful tool for designers, artists, and content creators in today's fast changing creative world, so let's dive in!
What is Flux?

Flux is a powerful model that can create detailed and realistic images from descriptions, text prompt, or other inputs. It's very flexible and works well with ComfyUI and Forge, both versatile interfaces for creating AI art. This makes it accessible not only to experts but also to beginners who might not have a technical background.

The image quality that FLUX produces is unmatched. It does a great job of understanding and following even the most complicated textual descriptions. It is amazing how well FLUX can handle accurate renders, abstract art, typography and a lot of other artistic styles and types of content.

Webinar: Intro to FLUX with Sebastian Kamph
Download the workflows for the webinar here:
Three Flavors of Flux AI

Flux AI comes in three flavors, each built for different needs:
- Flux Schnell: The Fastest. This is the basic, quick version similar to SDXL Lightning that uses a low number of steps, definitely optimized for speed. This model focuses on reducing generation time, possibly at the expense of some flexibility or advanced features, slightly compromising image quality to achieve faster generation times.
- Flux Dev: Flexible & high quality. When compared to Schnell, Dev excels at being more specific with its prompts, which is great for experimentation and prototyping. It prioritizes flexibility and ease of use over speed.
- Flux Pro: This is the premium edition, designed for enterprise and expert usage. This model aims to balance high-speed performance with advanced features and quality. It provide a competitive speed, possibly slower than Schnell but faster than Dev, while still maintaining high-quality output. It incorporates advanced algorithms and optimizations to ensure superior quality.
Model Quantization
Using the official flux1-dev.safetensors and flux1-schnell.safetensors model requires a machine with high VRAM and RAM. Model quantization is a technique that significantly reduces storage requirements, optimizing memory usage, speeding up computation, and lowering power consumption.
Below are some of the quantized variations and their comparisons:

- BNB-NF4-V2 - also known as Normalized Float 4, a quantized version released by @lllyasviel. Designed to be as efficient as possible, it delivers unmatched speed without sacrificing accuracy. You can speed up your workflows and do complicated jobs in a lot less time with this tool. It works well with less than 12GB VRAM.
- FP8 - also known as Float Point 8 released by @Comfy-Org and @Kijai, is much smaller than the original models and can run on 8GB VRAM without a noticeable drop in the quality of creating important text and details.
- F16, Q2, Q3, Q4, Q5, Q6, Q8 - also known as Georgi Gerganov Unified Format (GGUF), quantized versions developed by @city96. With more than 12GB of VRAM, the Q8 version creates a picture output with similar quality to FP16 at twice the speed. The Q4 version, on the other hand, can run on 8GB VRAM and gives you slightly better generation quality than NF4.
Clip Model
In order for FLUX workflows to work, you need to use a clip model like t5xxl_fp8_e4m3fn.safetensors or t5xxl_fp16.safetensors. Clip models from SDXL such as Clip L and Clip G are also used for the FLUX.
Google made T5xxL to handle a lot of different natural language processing jobs. It's great at jobs like translation, summarization, answering questions, and text generation. OpenAI is also working on Clip models, which learn visual ideas from how they are described in natural language.
How to Use FLUX
Platform Recommendation
It's highly recommended to use ComfyUI or Forge for FLUX text-to-image generation. In this guide we're going to use ComfyUI because it offers the most versatile interface.
One-Time Setup
Download the workflow above and drag & drop it into your ComfyUI window, whether locally or on ThinkDiffusion. If you're using ThinkDiffusion, it's necessary to use at minimum the Turbo 24gb machine, but we do recommend the Ultra 48gb machine.
Custom Nodes
If there are red nodes in the workflow, it means that the workflow is missing some required nodes. Install the custom nodes in order for the workflow to work.
- Go to ComfyUI Manager > Click Install Missing Custom Nodes
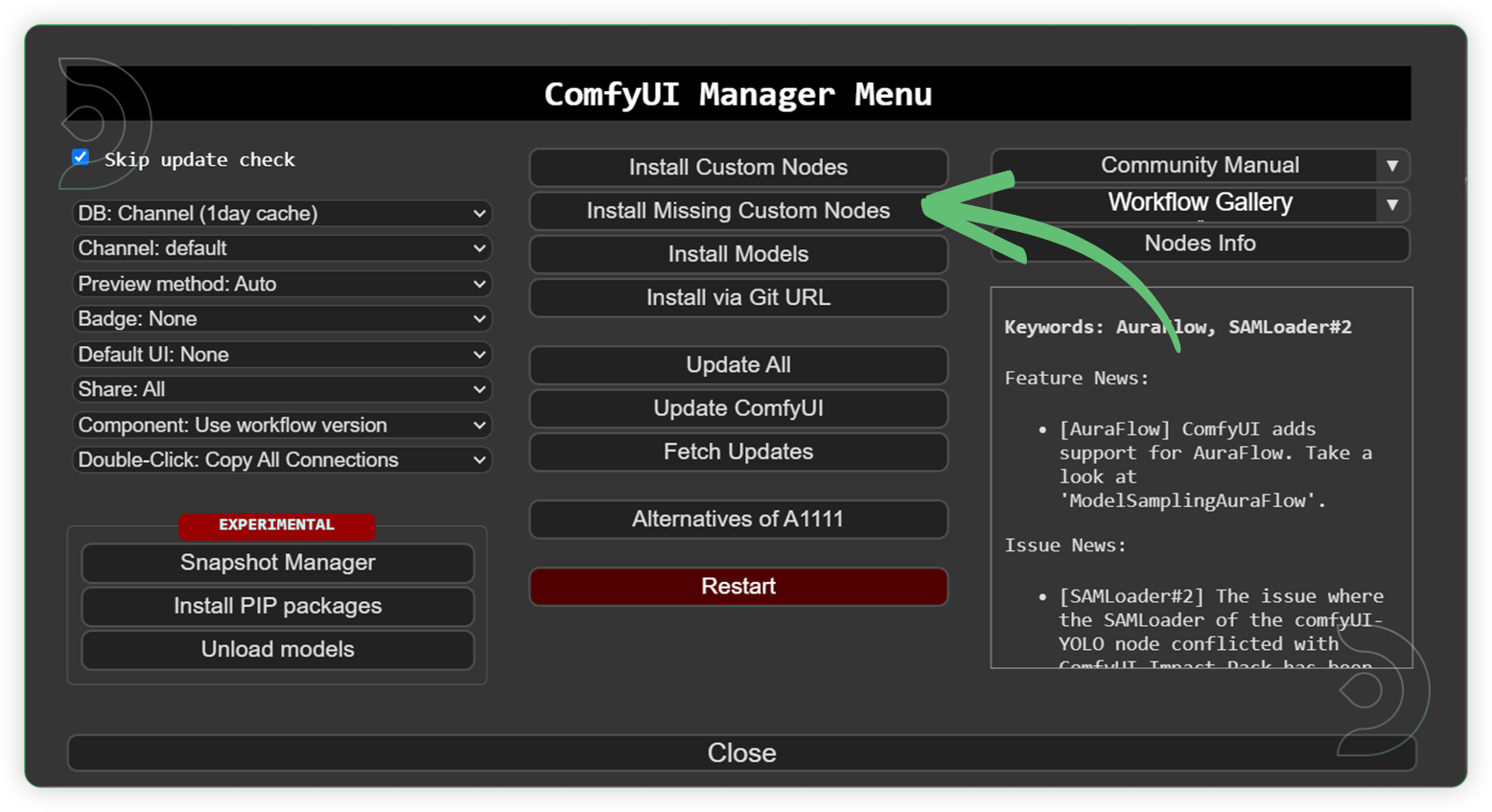
- Check the list below if there's a list of custom nodes that needs to be installed and click the install.

Models
Download the recommended models (see list below) using the ComfyUI manager and go to Install models. Refresh or restart the machine after the files have downloaded.
- Go to ComfyUI Manager > Click Install Models
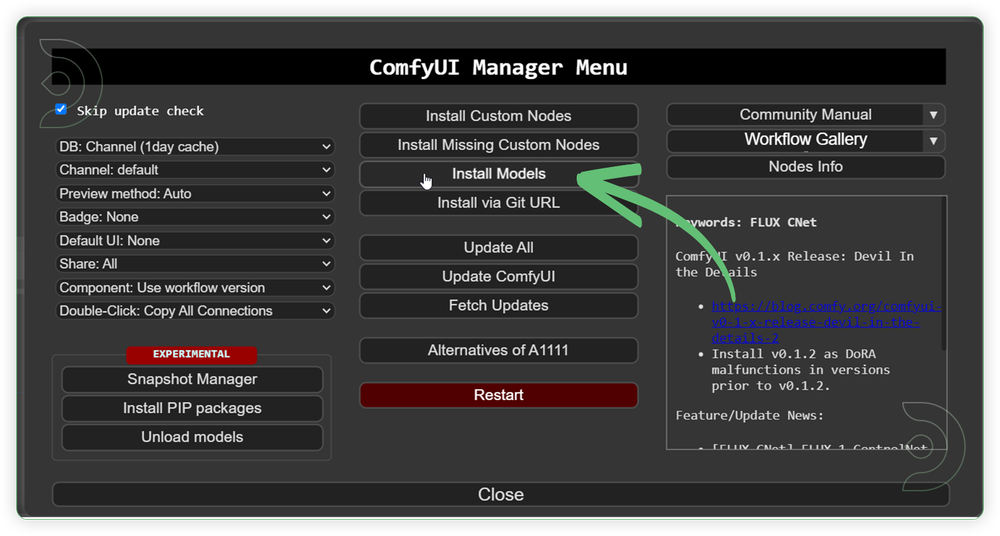
- When you find the exact model that you're looking for, click install and make sure to press refresh when you are finished.
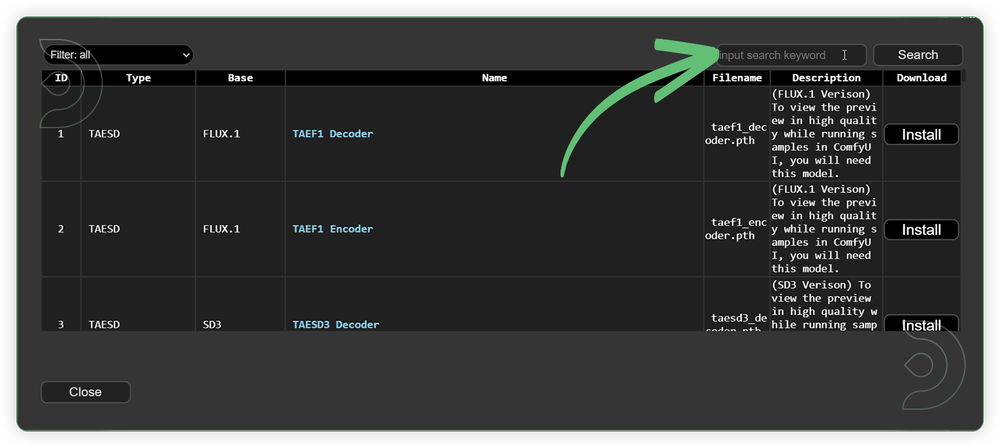
Model Path Source
Use the model path source if you prefer to install the models using model's link address and paste into ThinkDiffusion MyFiles using upload URL.
| Model Name | Model Link Address |
|---|---|
| flux1-dev.safetensors | |
| flux1-schnell.safetensors | |
| flux1-dev-fp8.safetensors | |
| flux1-schnell-fp8.safetensors | |
| flux1-dev-bnb-nf4-v2.safetensors | |
| flux1-dev-F16.gguf | |
| flux1-dev-Q2.gguf | |
| flux1-dev-Q3.gguf | |
| flux1-dev-Q4.gguf | |
| flux1-dev-Q5.gguf | |
| flux1-dev-Q6.gguf | |
| flux1-dev-Q8.gguf | |
| flux1-schnell-F16.gguf | |
| flux1-schnell-Q2.gguf | |
| flux1-schnell-Q3.gguf | |
| flux1-schnell-Q4.gguf | |
| flux1-schnell-Q5.gguf | |
| flux1-schnell-Q6.gguf | |
| flux1-schnell-Q8.gguf | |
| ae.safetensors | |
| t5xxl_fp8_e4m3fn.safetensors | |
| t5xxl_fp16.safetensors | |
| clip_l.safetensors |
Guide Table for Upload
Reminder
Procedures
Now that the hard work is out of the way, let's get creative. You need to follow the steps from top to bottom. The workflow is a one-click process after everything has been set up.
Guide for Original Models Workflow
| Steps | Description / Impact | Default / Recommended Values | Required Change |
|---|---|---|---|
| Select a Flux model | Specifies the name of the U-Net model to be loaded. This name is used to locate the model within a predefined directory structure, enabling the dynamic loading of different U-Net models. | 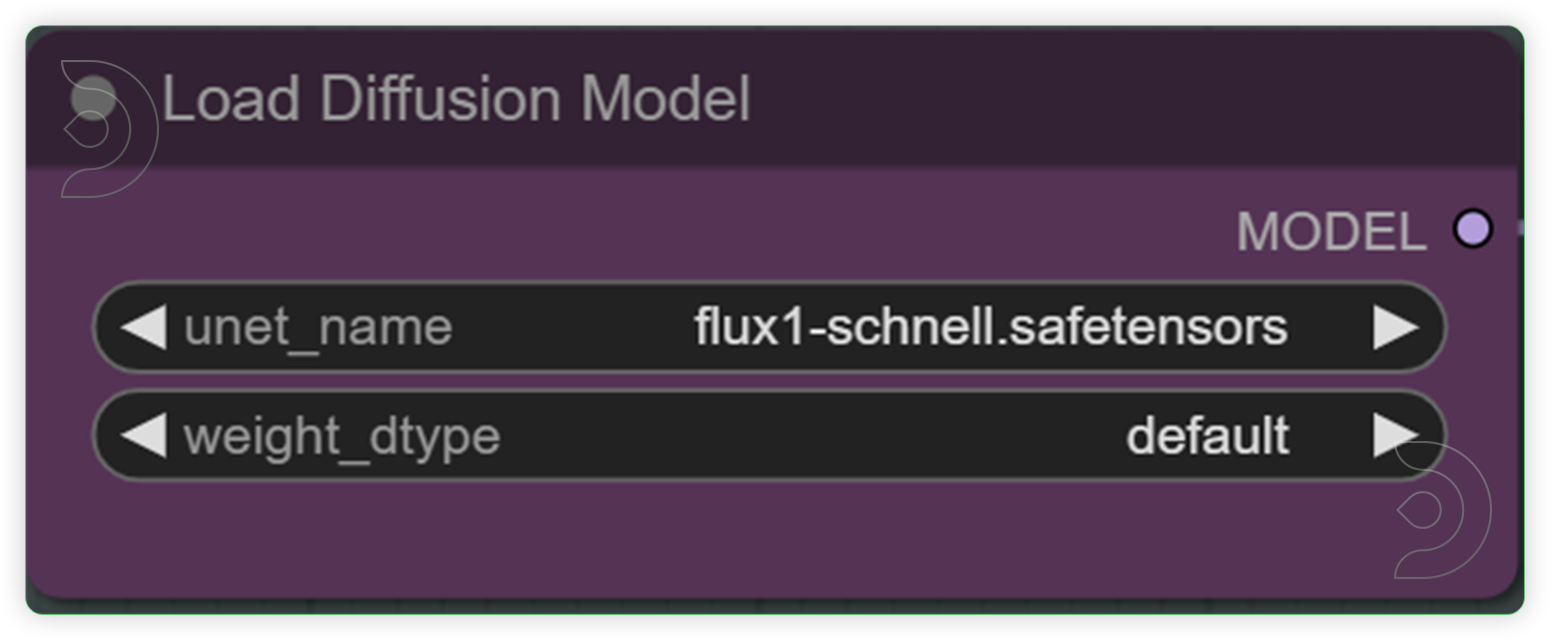 |
YES |
| Check and Select your desired dimension and batch size | Set the height and weight and this will be the basis for the generation output dimension. Batch size refers to the number of output per batch process. | 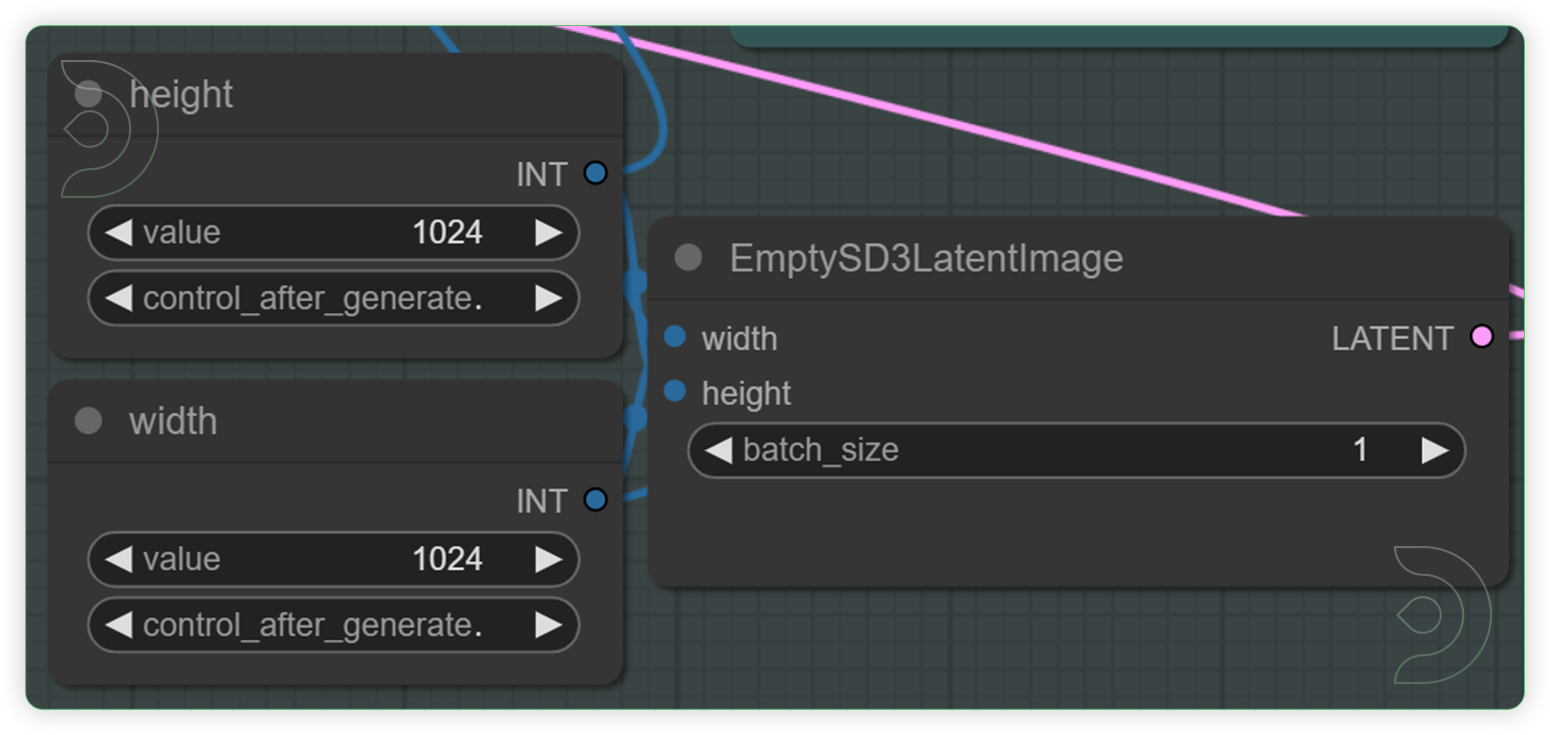 |
YES |
| Check the 4 nodes and set your preferred clip model. | ModelSamplingFlux adjusts the model's sampling behavior based on resolution and other parameters. DualCLIPLoader node is designed for loading two CLIP models simultaneously, facilitating operations that require the integration or comparison of features from both models. Highly recommend the euler and normal. | 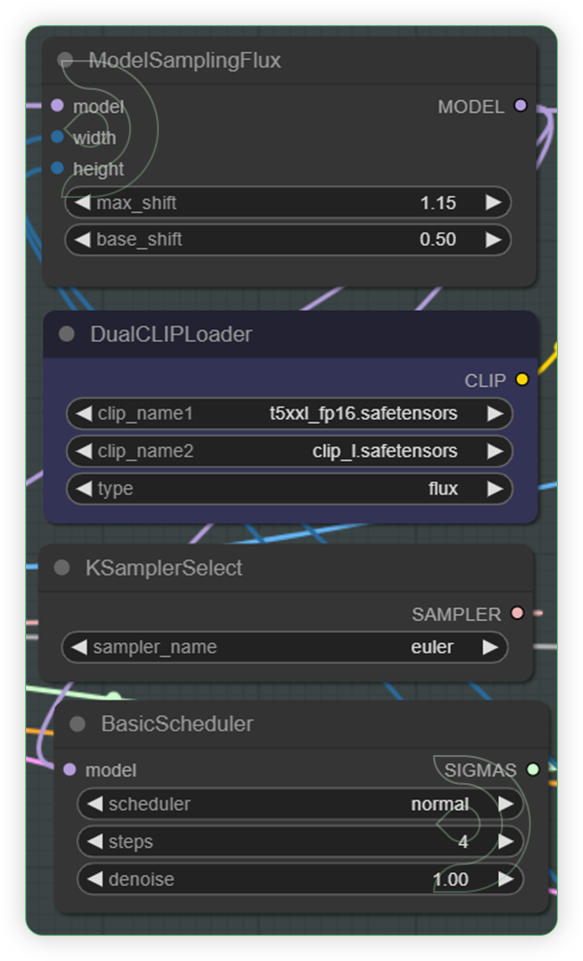 |
YES |
| Write a text prompt for Flux. Check the seed and its default fluxguidance. | The CLIP Text Encode node can be used to encode a text prompt using a CLIP model into an embedding that can be used to guide the diffusion model towards generating specific images. FluxGuidance assists in the image generation process. It is compared to the CFG (Control Flow Guidance) of Stable Diffusion, with the video script noting that it has a default value set lower than the CFG, affecting the generation process. | 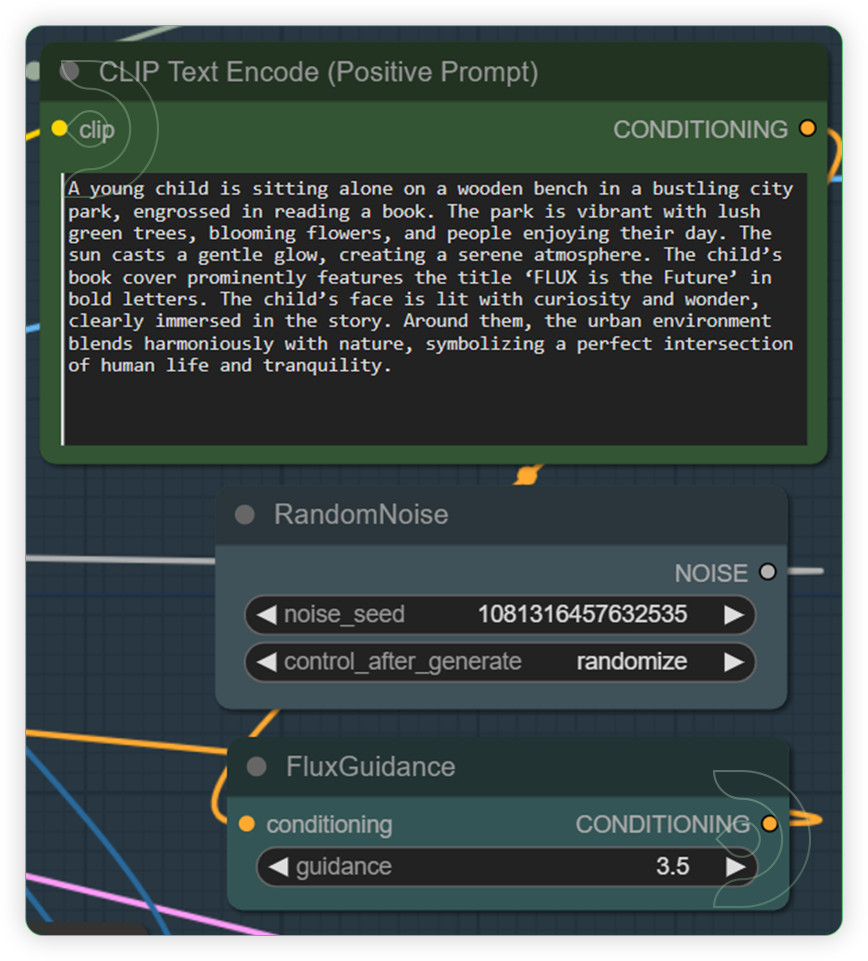 |
YES |
| Run the Queue Prompt |
Guide for FP8 and NF4 Workflow
| Steps | Description / Impact | Default / Recommended Values | Required Change |
|---|---|---|---|
| Use the Fast Bypasser for selecting a 1 Flux model. | Specifies the name of the U-Net model to be loaded based on the customized Fast Bypasser widget. This name is used to locate the model within a predefined directory structure, enabling the dynamic loading of different U-Net models. Enable only 1 model to process. | 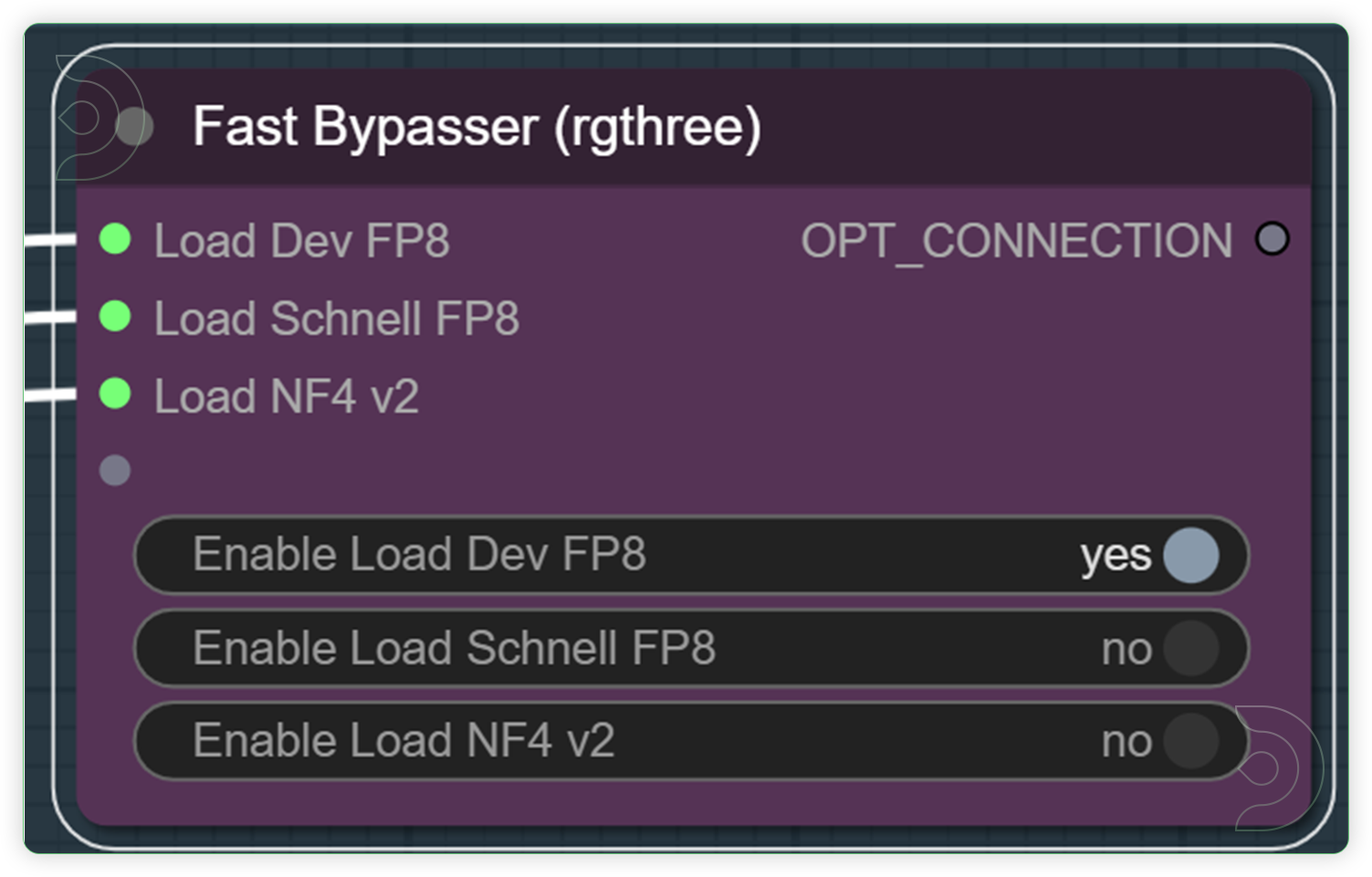 |
YES |
| Check and Select your desired dimension and batch size | Set the height and weight and this will be the basis for the generation output dimension. Batch size refers to the number of output per batch process. | 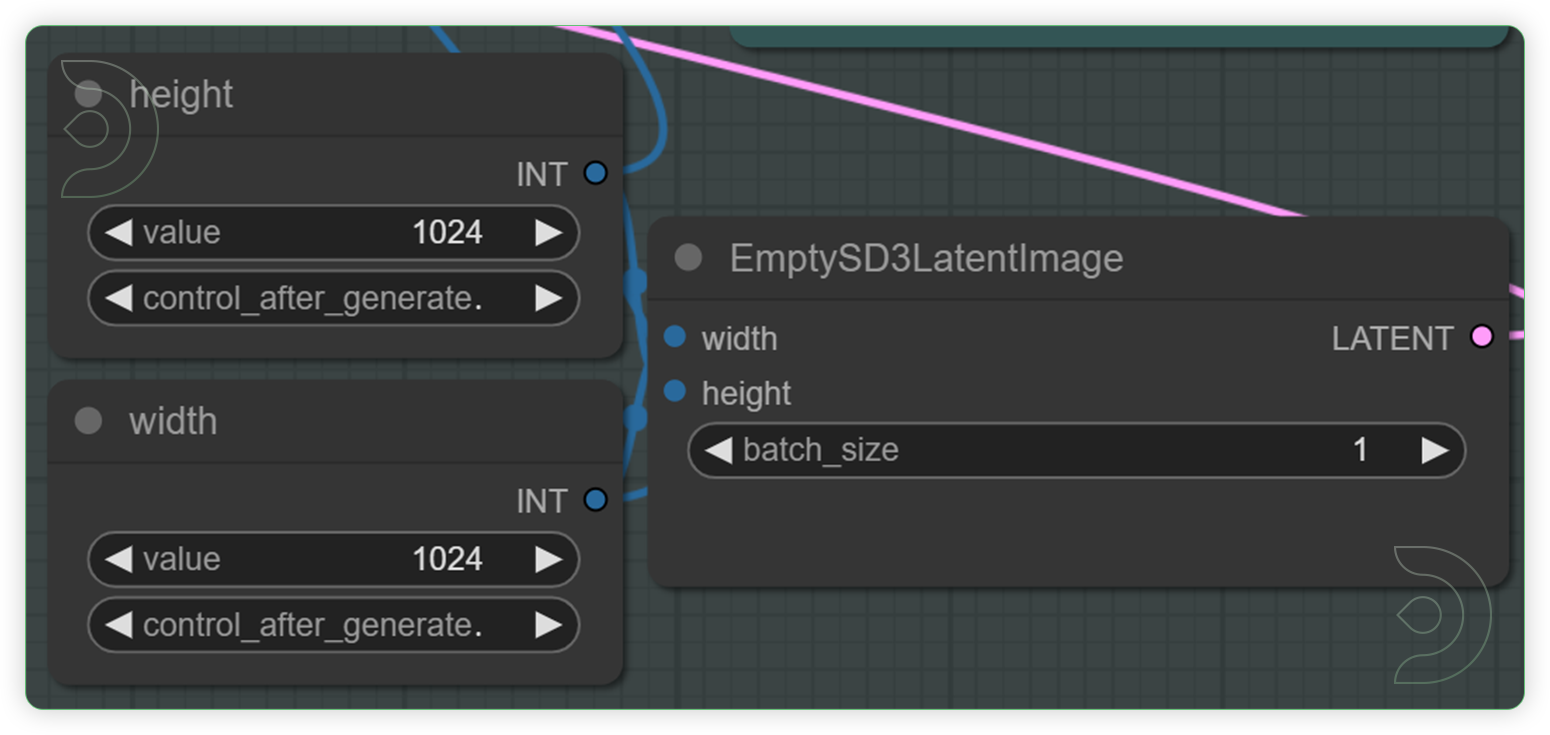 |
YES |
| Check the 4 nodes and set your preferred clip model. | ModelSamplingFlux adjusts the model's sampling behavior based on resolution and other parameters. DualCLIPLoader node is designed for loading two CLIP models simultaneously, facilitating operations that require the integration or comparison of features from both models. Highly recommend the euler and normal. | 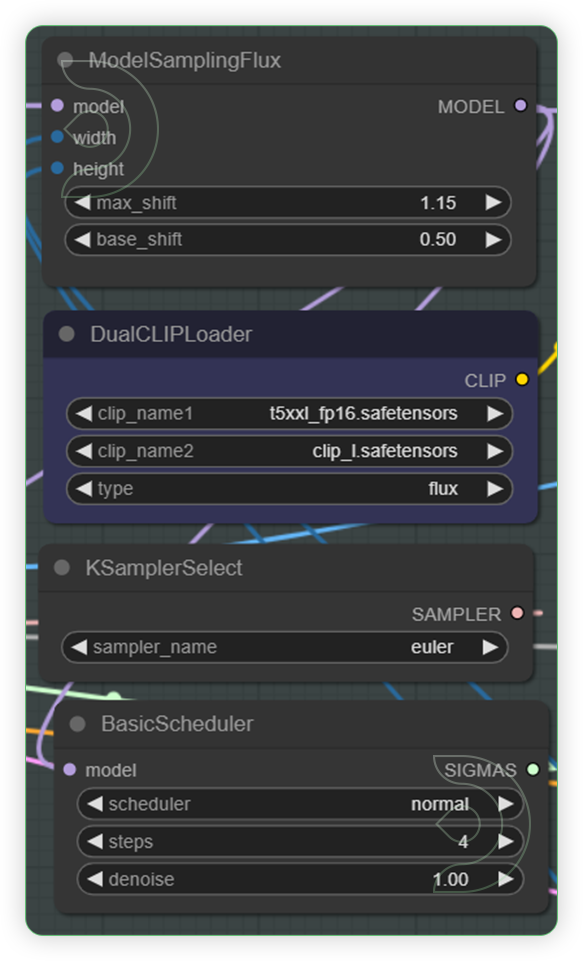 |
YES |
| Write a text prompt for Flux. Check the seed and its default fluxguidance. | The CLIP Text Encode node can be used to encode a text prompt using a CLIP model into an embedding that can be used to guide the diffusion model towards generating specific images. FluxGuidance assists in the image generation process. It is compared to the CFG (Control Flow Guidance) of Stable Diffusion, with the video script noting that it has a default value set lower than the CFG, affecting the generation process. | 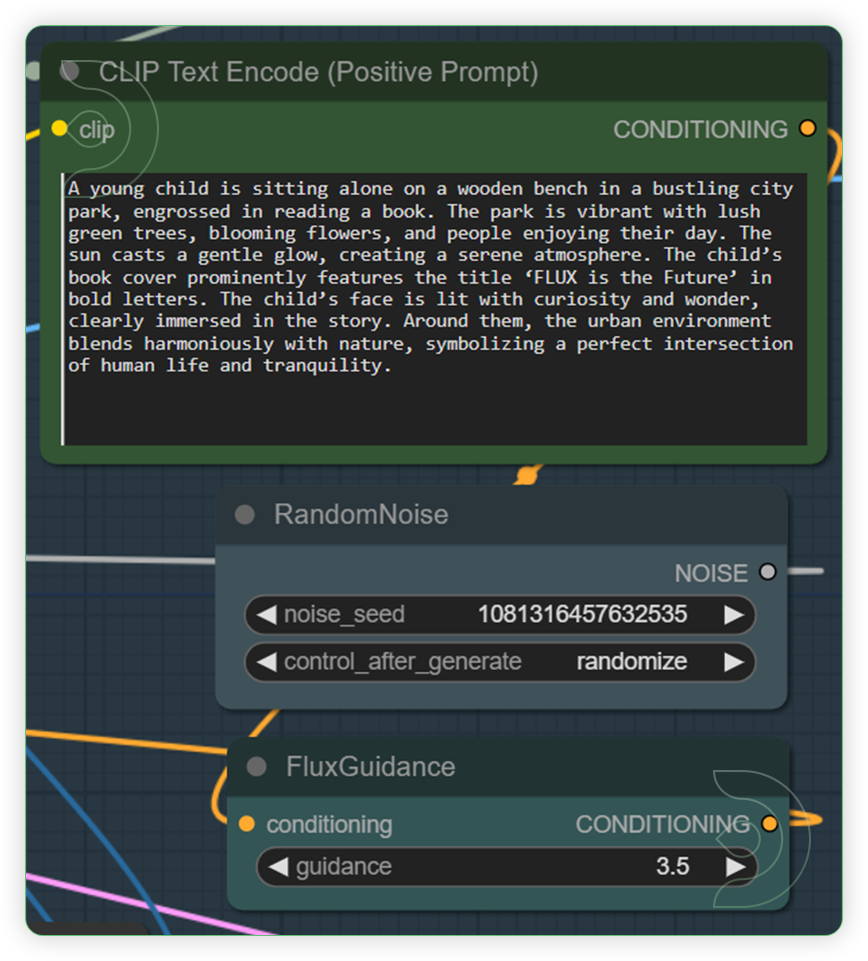 |
YES |
| Run the Queue Prompt |
Guide for GGUF Workflow
| Steps | Description / Impact | Default / Recommended Values | Required Change |
|---|---|---|---|
| Select a Flux model by using the Unet Loader GGUF and a select a 2 Clip model. | Specifies the name of the U-Net model to be loaded. This name is used to locate the model within a predefined directory structure, enabling the dynamic loading of different U-Net models. DualCLIPLoader node is designed for loading two CLIP models simultaneously, facilitating operations that require the integration or comparison of features from both models. Highly recommend the euler and normal. | 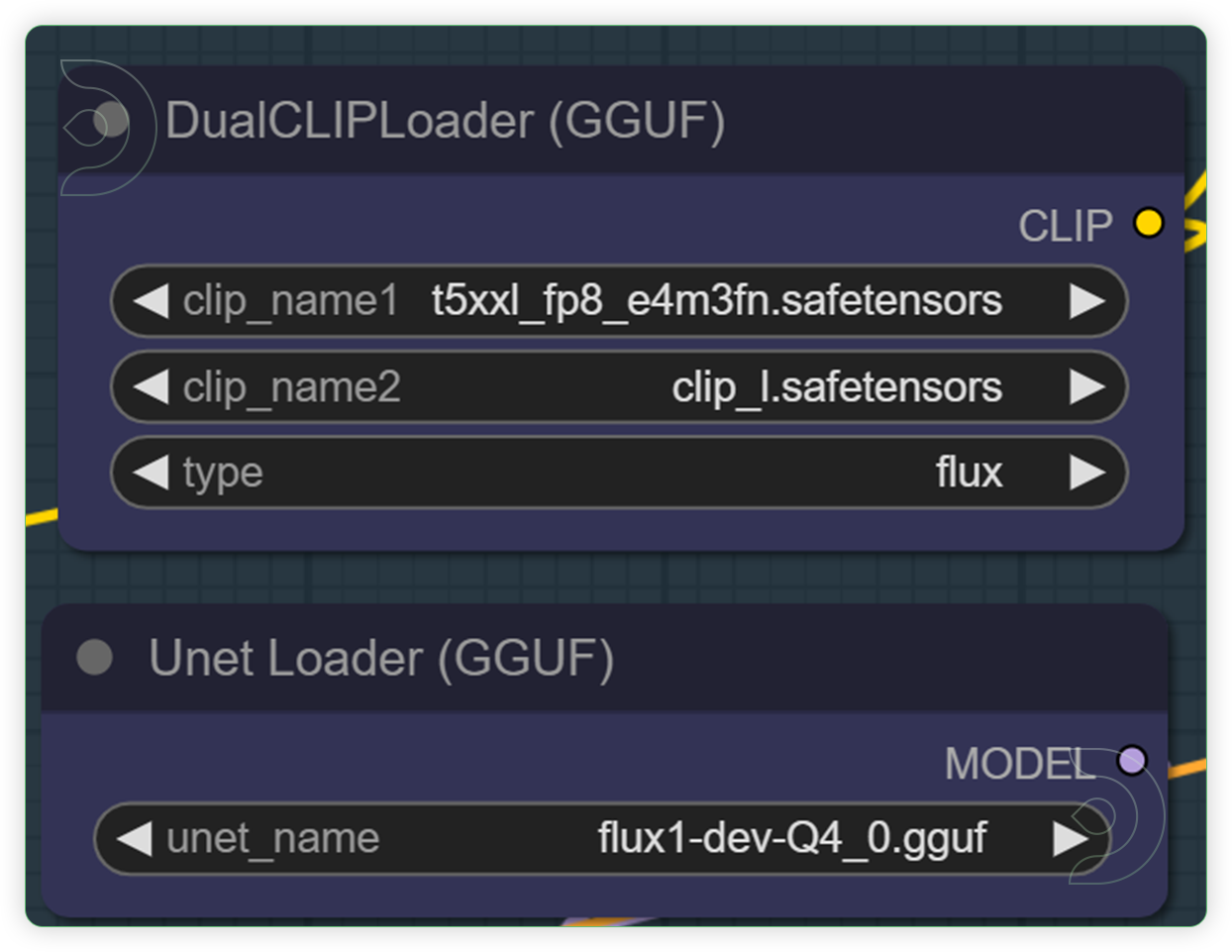 |
YES |
| Write a text prompt for Flux. Check the seed and its default fluxguidance. | The CLIPTextEncodeFlux node can be used to encode a text prompt using a CLIP model into an embedding that can be used to guide the diffusion model towards generating specific images. Guidance assists in the image generation process. It is compared to the CFG (Control Flow Guidance) of Stable Diffusion, with the video script noting that it has a default value set lower than the CFG, affecting the generation process. | 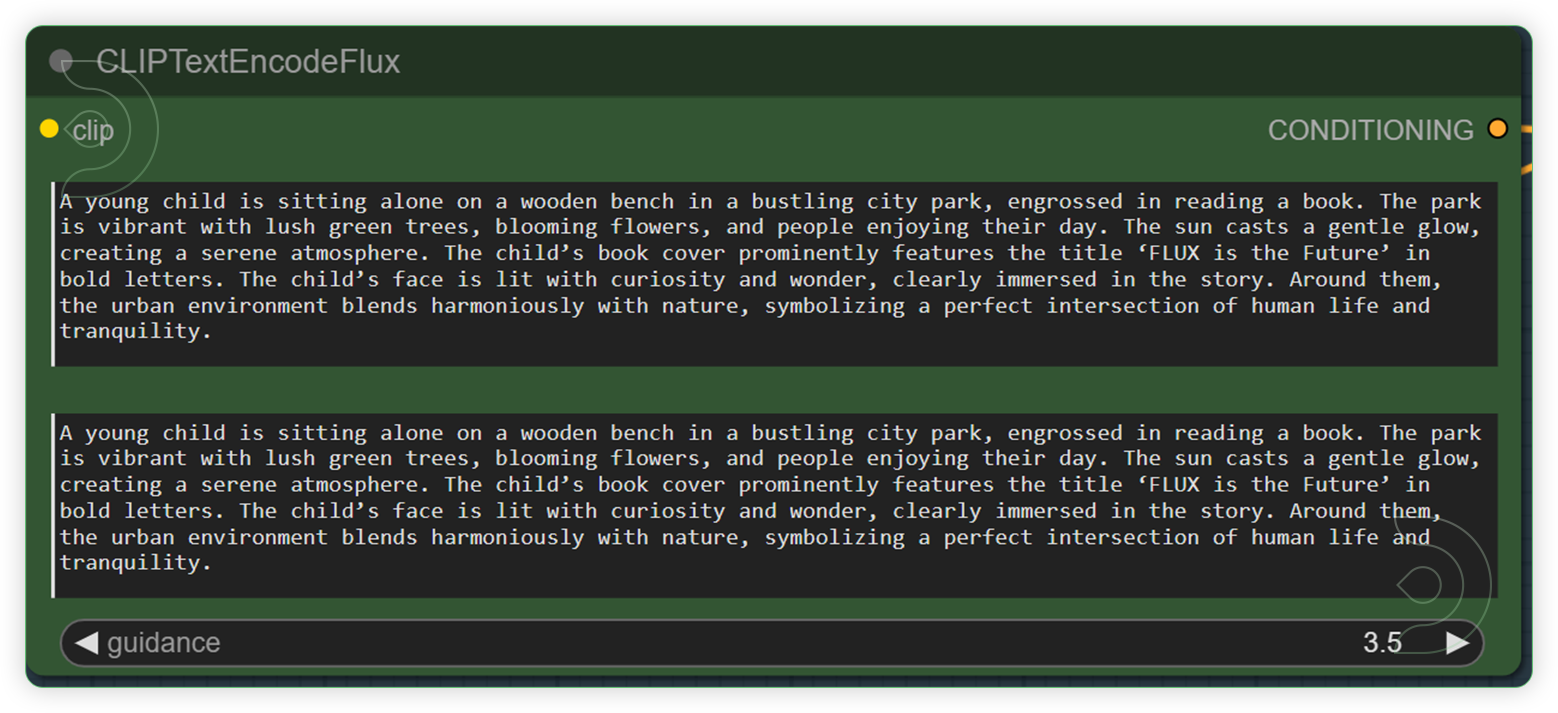 |
YES |
| Check the Ksampler and Resize Node | A modded KSampler efficient with the ability to preview/output images and run scripts. A node where you can set the Steps and CFG. | 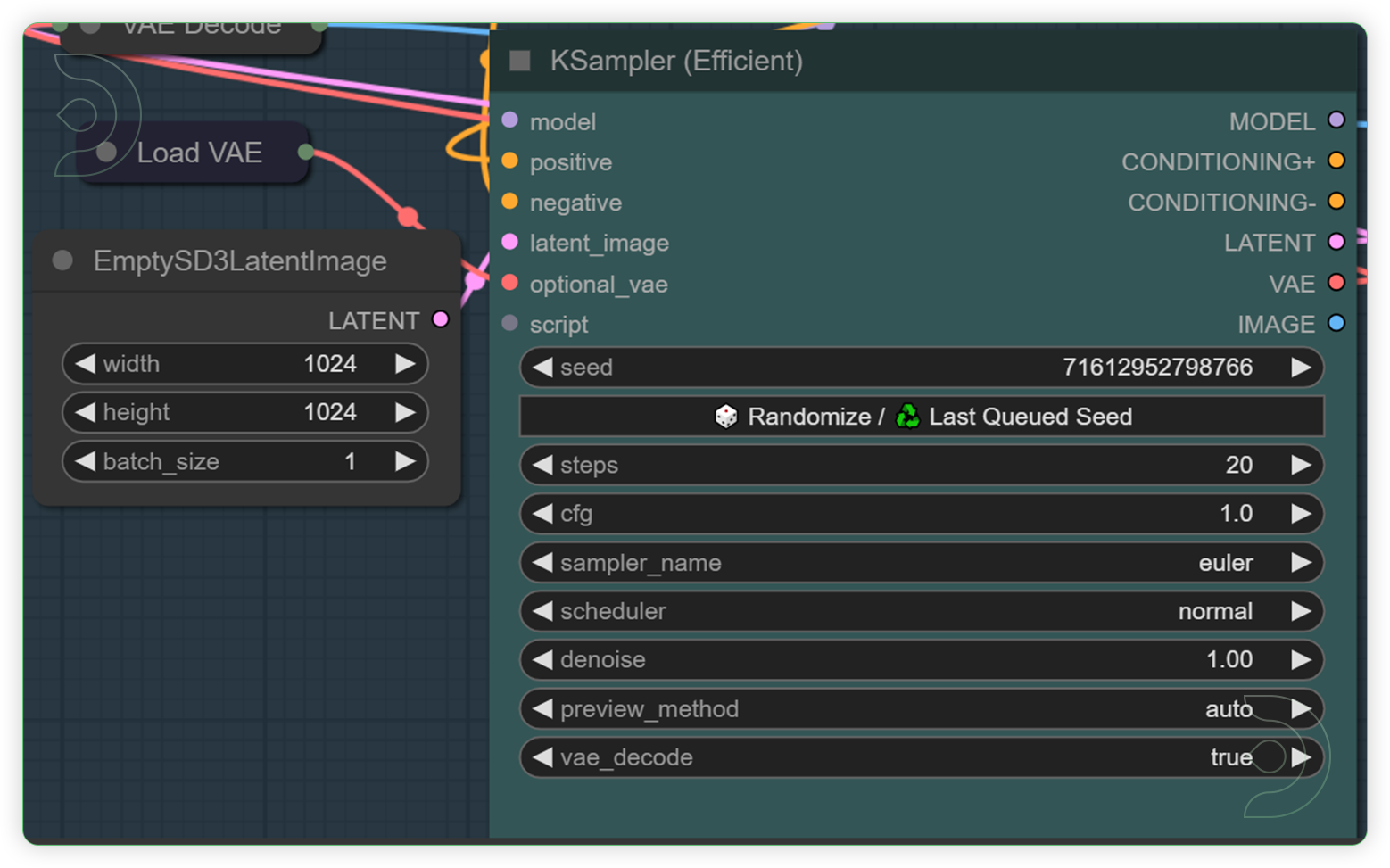 |
YES |
Flux AI Prompt Examples
You can check the examples below together with its prompt settings.




The Dense Jungle
Prompt - A dense jungle filled with exotic wildlife and towering trees. Parrots chatter from the canopy, and a narrow trail winds through thick foliage to a hidden waterfall cascading into a crystal-clear pool.
Model - flux1-schnell-Q8.gguf, Steps 20, CFG 1, Clip 1 - t5xxl-fp8, Clip 2 - Clip L, Seed - 71612952798766, Sampler - Euler, Scheduler - Normal, Denoise 1
The Newsroom Meeting
Prompt - A bustling newsroom, with reporters hurrying to meet deadlines and phones ringing incessantly. Papers are scattered across desks, and large screens display breaking news from around the world.
Model - flux1-dev-Q8.gguf, Steps 20, CFG 1, Clip 1 - t5xxl-fp8, Clip 2 - Clip L, Seed - 1084972251415857, Sampler - Euler, Scheduler - Normal, Denoise 1
The Japanese Garden
Prompt - A serene Japanese garden in springtime, complete with cherry blossoms in full bloom. A stone path winds through manicured greenery, leading to a tranquil koi pond and a traditional tea house.
Model - flux1-dev-bnb-nf4.safetensors, Steps 20, CFG 1, Clip 1 - t5xxl-fp8, Clip 2 - Clip L, Seed - 1066588834590345, Sampler - Euler, Scheduler - Normal, Denoise 1
The Crowded Carnival
Prompt - A crowded carnival at dusk, with the sounds of laughter and the smell of popcorn in the air. Brightly colored rides and game booths line the midway, and the Ferris wheel lights up against the darkening sky.
Model - flux1-dev-bnb-nf4.safetensors, Steps 30, CFG 1, Clip 1 - t5xxl-fp16, Clip 2 - Clip L, Seed - 635804676789378, Sampler - Euler, Scheduler - Normal, Denoise 1
Frequently Asked Questions on FLUX AI
- Can you use LoRA models with Flux?
Yes, but you need Flux-specific LoRAs - older Stable Diffusion LoRAs won't work.
Here's how to use a LoRA in your workflow:
• Add a "Load LoRA" node between your "KSampler" and "VAE Decode" nodes • Connect the CLIP from the "CLIP Text Encode" node to the LoRA node
• Select your Flux LoRA in the settings
You can chain multiple LoRAs for more complex effects. We've included a sample workflow with LoRA integration in our downloadable files. - How does Flux compare to Stable Diffusion?
Flux, being newer, has surpassed Stable Diffusion in several ways:
- Better out-of-the-box generations
- Improved text understanding and generation
- 16-channel VAE (compared to Stable Diffusion's 4-channel), resulting in better details
- Native resolution of 1024x1024
- Improved handling of hands, feet, and other details However, Flux is more resource-intensive and has fewer extensions available due to its newness.
- What's the difference between Forge and ComfyUI, and which one should I use?
Both have their strengths:
Forge: Similar to Automatic1111, better for tasks like inpainting, and easier for beginners or those familiar with Photoshop-style interfaces.
ComfyUI: More flexible and powerful, allowing for custom workflows and advanced features. Better for complex tasks or creating unique generation pipelines. Sebastian uses both, depending on the task. For quick edits or inpainting, Forge might be preferable. For custom workflows or advanced techniques, ComfyUI is the go-to option. - How does Flux handle consistent characters across multiple generations?
Flux generally performs better at maintaining consistency compared to older Stable Diffusion models. However, for the best results in character consistency, you might want to explore techniques like using LoRAs trained on specific characters or utilizing img2img workflows with a base character image.
Resources
It contains the samples of generated Flux art.
If you’re having issues with installation or slow hardware, you can try any of these workflows on a more powerful GPU in your browser with ThinkDiffusion.
If you enjoy ComfyUI and you want to test out creating awesome animations, then feel free to check out this AnimateDiff tutorial here.
Member discussion