

Prompt: A shy apprentice mage, cloaked in tattered robes, stands beside a glowing portal deep within a misty, enchanted forest at twilight. Strange fireflies flicker around ancient twisted trees, and distant magical runes pulse gently on mossy stones. The camera spirals in from above, capturing the mage’s hesitant gestures as arcane sparks dance between their fingers. The sound of whispering leaves and a faint, mystical melody fills the air—immersing viewers in a fantastical, atmospheric scene with lifelike lighting, rich magical effects, and cinematic visual storytelling.
Type a scene description, get a video. That's Wan2.2.
This is an open-source text-to-video model that uses a Mixture-of-Experts system to create realistic motion and accurate visuals. It handles 720p videos with smoother animation and fewer artifacts than version 2.1, and it runs on standard GPUs without needing a server farm.
Describe a fantasy world, a dramatic scene, or something everyday—Wan2.2 turns it into video. Works well for storyboarding, concept testing, or just seeing your ideas move.
What we'll cover
- What Wan2.2 is and how it's better than 2.1
- Getting the workflow running on ThinkDiffusion
- Installing the 6 models you need
- Walking through the workflow settings
- Real video examples across different styles
- Common issues and fixes
The Wan2.2 Release
Wan2.2 is a next-generation, open-source text-to-video model featuring a Mixture-of-Experts (MoE) system for dramatically more realistic motion, prompt accuracy, and cinema-quality visuals compared to Wan2.1. With much larger training data and smart MoE design, it delivers fluid, artifact-free 720p videos quickly and efficiently, even on standard GPUs. Artists, animators, filmmakers, and creators at any level will find Wan2.2 superior for its greater detail, smoother animation, and enhanced creative control—making it the go-to tool for high-quality, prompt-driven video generation.
Prompt: A teenage boy in a faded hoodie bicycles down a rain-slicked suburban street under a brooding twilight sky. The houses’ windows glow warmly as he pedals past, his breath visible in the cold air. The camera tracks alongside at wheel level, water spraying from the tires and reflecting streetlights. Wind ruffles fallen leaves, dogs bark in the distance, and the sound of passing cars merges with distant thunder—evoking a moody, authentic suburban scene with nuanced lighting and a strong sense of realism.
Whether you’re experimenting with fantasy worlds, dramatic scenes, or lifelike moments that pulse with real atmosphere, prepare to be amazed—because with Wan2.2, the magic of cinematic video is just a sentence away waiting to be brought to life by your imagination alone.
Download Workflow
Installation guide
- Download the workflow file
- Open ComfyUI (local or ThinkDiffusion)
- Drag the workflow file into the ComfyUI window
- If you see red nodes, install missing components:
- ComfyUI Manager > Install Missing Custom Nodes
Verified to work on ThinkDiffusion Build: July 9, 2025
ComfyUI v0.3.47 with the use wan2.2_t2v_high_noise_14B_fp8_scaled.safetensors and wan2.2_t2v_low_noise_14B_fp8_scaled.safetensors, and with these LoRAs high_noise_model.safetensors and low_noise_model.safetensors
Note: We specify the build date because ComfyUI and custom node versions updated after this date may change the behavior or outputs of the workflow.
Minimum Machine Size: Ultra
Use the specified machine size or higher to ensure it meets the VRAM and performance requirements of the workflow
Custom Nodes
If there are red nodes in the workflow, it means that the workflow lacks the certain required nodes. Install the custom nodes in order for the workflow to work.
- Go to the ComfyUI Manager > Click Install Missing Custom Nodes
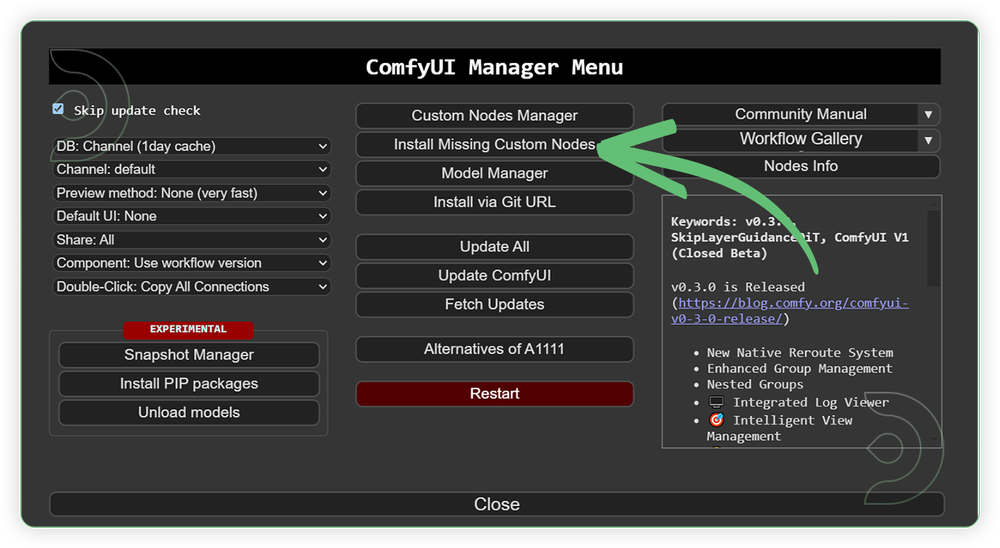
- Check the list below if there's a list of custom nodes that needs to be installed and click the install.
Required Models
For this guide you'll need to download these 6 recommended models.
2. wan2.2_t2v_low_noise_14B_fp8_scaled.safetensors
3. umt5-xxl-enc-bf16.safetensors
4. wan_2.1_VAE_bf16.safetensors
5. high_noise_model.safetensors
6. low_noise_model.safetensors
- Go to ComfyUI Manager > Click Model Manager
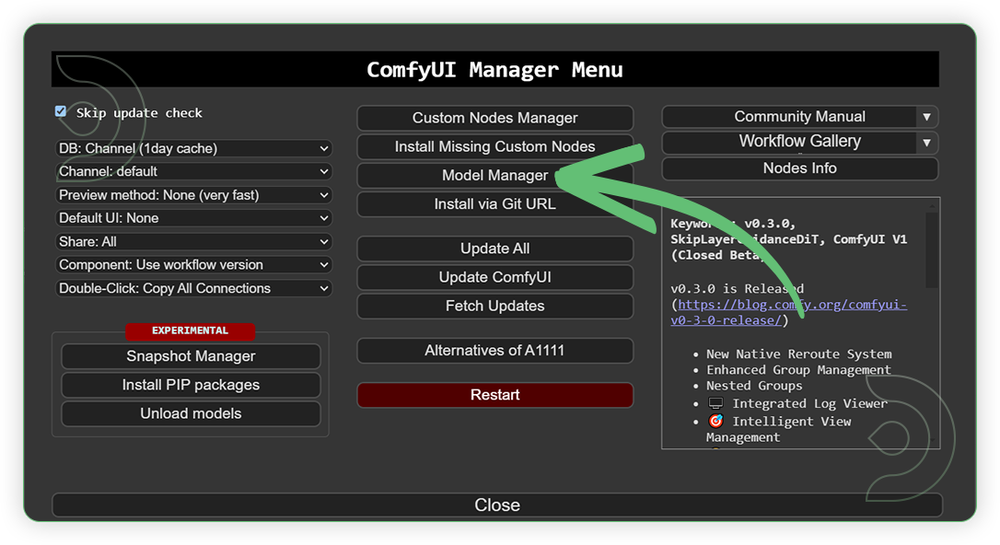
- Search for the models above and when you find the exact model that you're looking for, click install, and make sure to press refresh when you are finished.
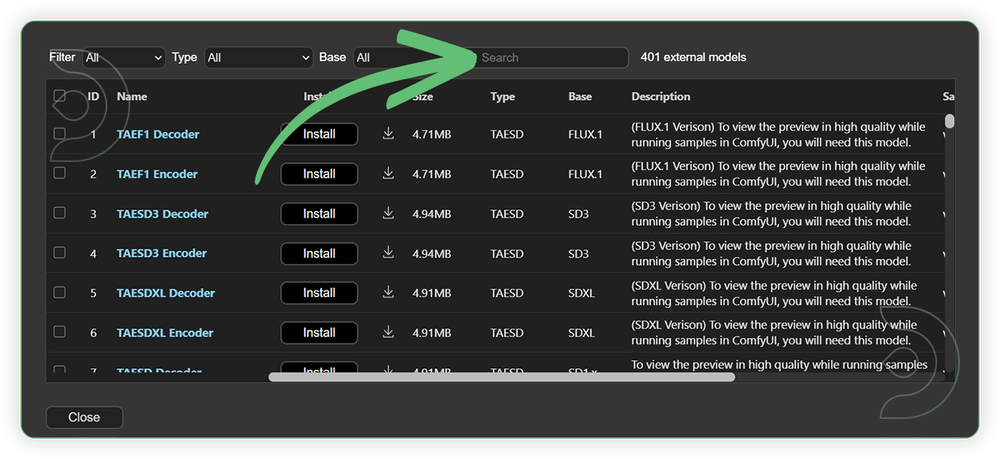
If Model Manager doesn't have them: Use direct download links (included with workflow) and upload through ThinkDiffusion MyFiles > Upload URL. Refer our docs for more guidance on this.
You could also use the model path source instead: by pasting the model's link address into ThinkDiffusion MyFiles using upload URL.
| Model Name | Model Link Address | ThinkDiffusion Upload Directory |
|---|---|---|
wan2.2_t2v_high_noise_14B_fp8_scaled.safetensors |
.../comfyui/models/diffusion_models/ |
|
| wan2.2_t2v_low_noise_14B_fp8_scaled.safetensors | .../comfyui/models/diffusion_models/ |
|
| umt5-xxl-enc-bf16.safetensors | .../comfyui/models/text_encoders/ |
|
| wan_2.1_VAE_bf16.safetensors | .../comfyui/models/vae/ |
|
| high_noise_model.safetensors | .../comfyui/models/lora/ |
|
| low_noise_model.safetensors | .../comfyui/models/lora/ |
Step-by-step Workflow Guide
This workflow was pretty easy to set up and runs well from the default settings. Here are a few steps where you might want to take extra note.
| Steps | Recommended Nodes |
|---|---|
| 1. Set the Models Set the models as seen on the image. Enabled the low mem load if you experienced the out of memory. |
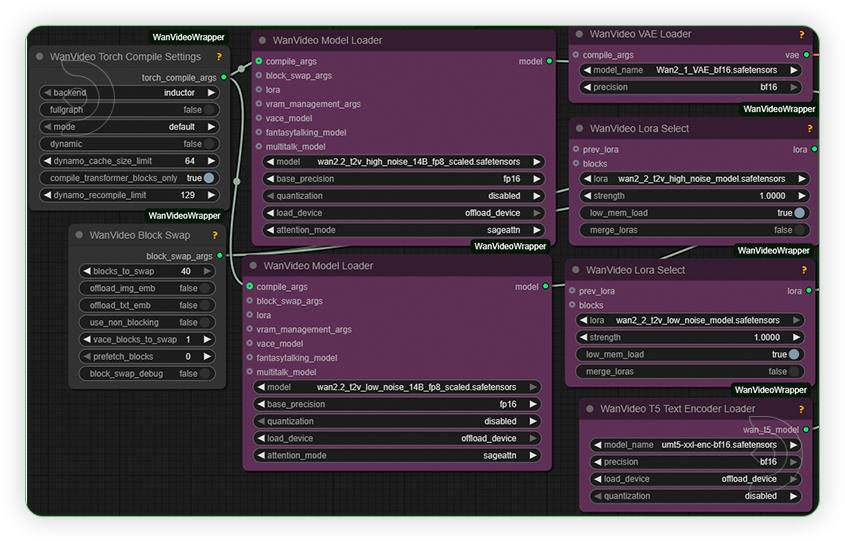 |
| 2. Write a Prompt Write a detailed prompt. Wan2.2 model is good in adherence of prompt. Set the size to 480p only. Wan2.2 is compatible with 720 and 1080 resolution and higher frames but you need a higher machine for that. |
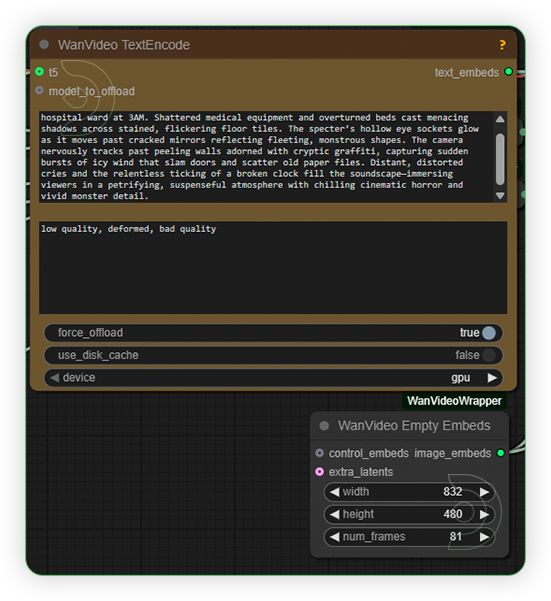 |
| 3. Check Sampling Set the sampling setting as seen on the image. Since it uses a lightning x2v lora, the inference steps should be at 4 only. Otherwise, it will result to an error. |
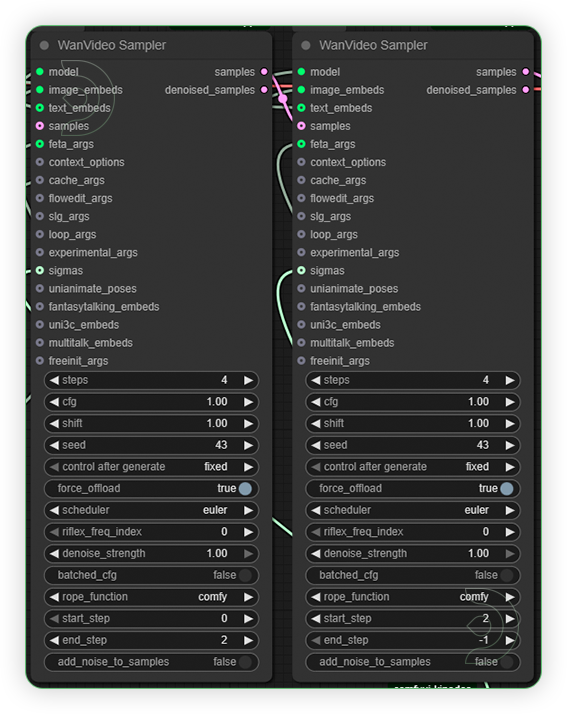 |
| 4. Check the Video |
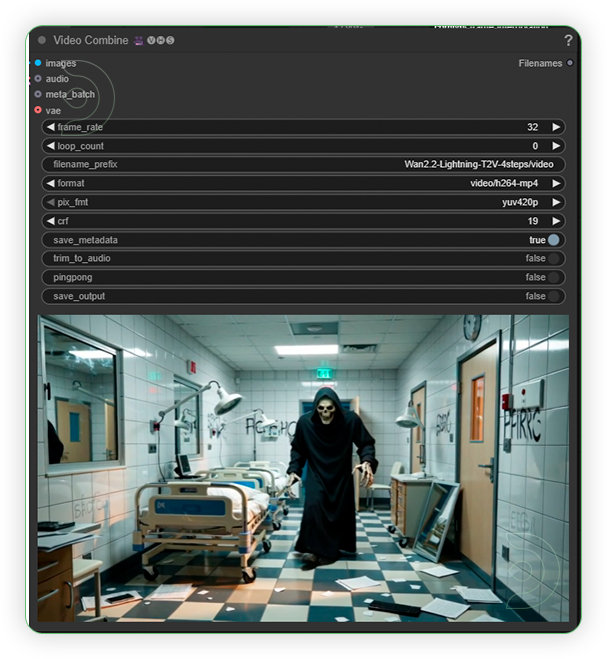 |
Examples
Prompt: A curious animated raccoon wearing a tiny yellow raincoat tiptoes through a moonlit alley crowded with overflowing trash bins and twinkling puddles. Neon reflections shimmer on slick cobblestones as the raccoon sniffs around, occasionally startled by animated cats darting past or cans tumbling noisily. The camera follows low to the ground, highlighting the raccoon’s expressive eyes, fluffy tail, and gentle paws. Soft jazz plays in the background, muffled by distant city hum, enriching the whimsical, atmospheric animated scene with vivid nighttime textures and lively character animation.
Prompt: A timid maintenance worker, clutching a flashlight, descends into a labyrinthine subway tunnel after midnight. Shadows creep along cracked tiles and ancient graffiti as unnatural screeches echo from deep within the darkness. The camera pans slowly through the eerie silence, glancing over the worker’s terrified face just as a monstrous, skeletal creature with glowing eyes slithers from the shadows behind rusted pipes. Flickering lights reveal jagged claws and a sinister grin, while the tunnel fills with chilling whispers, distant thunder, and heart-pounding footsteps—immersing viewers in a suspenseful, terrifying scene with detailed, cinematic horror atmosphere and truly frightening monster realism.
Prompt: A cheerful animated robot with bright, glowing eyes and spindly limbs bounces across a moonlit carnival filled with oversized balloons and swirling rides. Colorful lights flash across the robot’s reflective body as it weaves between laughing animated animals and swirling confetti. The camera smoothly follows its energetic movements, capturing sparks that fly from its hands as it dances on a spinning carousel. Background music mixes playful electronic beats with distant giggles, bringing the whimsical animated scene to life with vivid detail, dynamic lighting, and expressive character animation.
Prompt: A reserved florist in an apron quietly arranges bouquets in her shop during a gentle afternoon rain. Outside, a young musician stands beneath the awning, strumming a soft tune as passersby hurry past. The camera glides from the rain-dappled window to the florist’s thoughtful smile, then out to the musician meeting her gaze. Petals scatter on the countertop, rain streaks the glass, and the subdued city sounds blend with tender chords—creating an intimate, atmospheric romance scene, brought to life with authentic lighting, emotion, and cinematic mood.
Prompt: A retired detective in a worn trench coat quietly surveys an abandoned train station shrouded in thick morning fog. He holds an old photograph, scanning empty benches and flickering overhead lights. The camera moves slowly between cracked tiles and rusty tracks, focusing on the detective’s tense posture and sharp gaze. Distant echoes of footsteps, the hum of departing trains, and swirling mist fill the soundscape—creating a suspenseful, moody mystery scene with cinematic depth, authentic atmosphere, and lifelike environmental details.
Prompt: A weary space mechanic, dressed in a patched jumpsuit, floats outside a battered starship as a nebula glows in the distance. His helmet visor reflects flickers from distant lightning storms. The camera glides slowly along the hull, capturing him making delicate repairs against the eerie, luminous backdrop. Tools drift beside him, while transmission crackles and distant alarms layer the soundscape. Each movement creates swirling flashes of color and shadow—evoking the tension and isolation of sci-fi space travel with atmospheric, movie-quality lighting and realistic technical detail.
Prompt: An exhausted firefighter, his face streaked with soot and sweat, stands in the middle of a rain-soaked street at night. Neon signs flicker in the hazy background as emergency lights flash across glistening puddles. The camera starts at ground level, slowly dollying upward and forward to frame the firefighter’s determined expression in close-up. Street reflections shimmer, rain falls gently, and distant sirens echo—capturing an atmosphere of tension, resilience, and gritty realism with movie-grade lighting and natural color grading.
Troubleshooting
Red Nodes: Install missing custom nodes through ComfyUI Manager
Out of Memory (Allocation on Device error): Use smaller expansion factors, lower resolution, or less frames. Optionally try higher VRAM machines such as ULTRA or newly available NITRO (beta feature). Note that even with more VRAM, you may still encounter out-of-memory issues with Wan2.2.
Poor Quality: Check input image resolution and adjust kontext strength
Visible Seams: Lower strength and ensure good prompt description
If you’re having issues with installation or slow hardware, you can try any of these workflows on a more powerful GPU in your browser with ThinkDiffusion.
If you're having issues with workflow and visit us here at Discord #Help Desk or you may opt to email us at support@thinkdiffusion.com

Member discussion