

You can find the latest release notes in reverse chronological order here. This is a good way to see the detailed descriptions of new features, enhancements, and bug fixes. Join our Discord to see the latest announcements.
December 15, 2024
Hey @everyone how are you all easing into the holiday season...Just wanted to drop a quick update -
When?
Wednesday, 18 Dec
9 AM PST
What?
Join Sebastian for 45 minutes exploring what's actually possible when you combine Flux's quality with precise control.
Why Flux ControlNet?
- Detailed control: Guide AI while keeping FLUX's signature quality. No more fighting with settings or endless retries.
- Endless applications: Whether you're refining product shots or creating concept art, ControlNet adapts to your creative process.
- Unmatched versatility: Shape everything from composition to lighting with precision. Depth maps, edge control - whatever your project needs.
Can't wait to see you guys there! Do add it to your calendar so you get reminders.
👉 Register here -> https://lu.ma/3uyex89b
December 12, 2024
Hi @everyone! We have a couple of cool things to share with you..
- Blip Captioning
- To caption images using BLIP, store all images in a dedicated folder (e.g.,
/home/ubuntu/user_data/kohya/image) and ensure Kohya recognizes the path by prepending/home/ubuntu/. - Click Caption Images to begin.
- Monitor the logs for progress, and once "captioning done" appears, your captions are ready.
- To caption images using BLIP, store all images in a dedicated folder (e.g.,
- Dataset Preparation
- After BLIP captioning, go to the LoRA -> Training tab and select Dataset Preparation.
- Enter instance and class prompts, input paths for training images, regularization images, and output folder, and set the number of repeats.
- Click Prepare training data to organize files and then use Copy info to respective fields to proceed with training.
- Load/Save Config file
- This step is crucial for training your LoRA with Flux, as skipping it may lead to Out of Memory issues.
- You can upload your config file to
kohya/configsand go to the Configuration tab. - Under Load/Save Config file, paste the config file path (e.g.,
../user_data/kohya/configs/flux_td.json) and click the ↩️ icon to load it. - For Config file Click Here
- Start Training
- Simply trigger Start Training (keep checking the logs) & congratulations you are able to train your first Flux LoRA model.
- The generated model will be saved at
../user_data/kohya/output/model
- Tensorboard - With the help of Tensorboard one can visualize and track information about the model.
- Click on Start Tensorboard to start the Tensorboard service
- To view the generated Tensorboard, you will need to open it in a new tab.
- First grab/copy your machine id which is the last part of your machine URL:
https://www.thinkdiffusion.com/sd/<machine_name>, - Open a new tab and enter the a new url using your machine id machine id:
http://<machine_id>.thinkdiffusion.xyz:6006/(note the port that Tensorboard will be running on is 6006).
- First grab/copy your machine id which is the last part of your machine URL:
We will soon be releasing a detailed Flux LoRA training tutorial.
Start fine-tuning your models effortlessly by launching your Kohya Machine under Beta Section
If you’d like to use these models, you can either access them via the console or integrate fal.ai directly into ComfyUI using a custom node.
Steps to integrate fal in ComfyUI:
-
Install ComfyUI-fal-API custom node.
-
Get your fal API key from fal.ai
-
Open the
config.inifile in the root directory of this project -
Replace <your_fal_api_key_here> with your actual fal API key:
[API] FAL_KEY = your_actual_api_key -
After installation and configuration, restart ComfyUI. The new nodes will be available in the node browser under the "FAL" category.
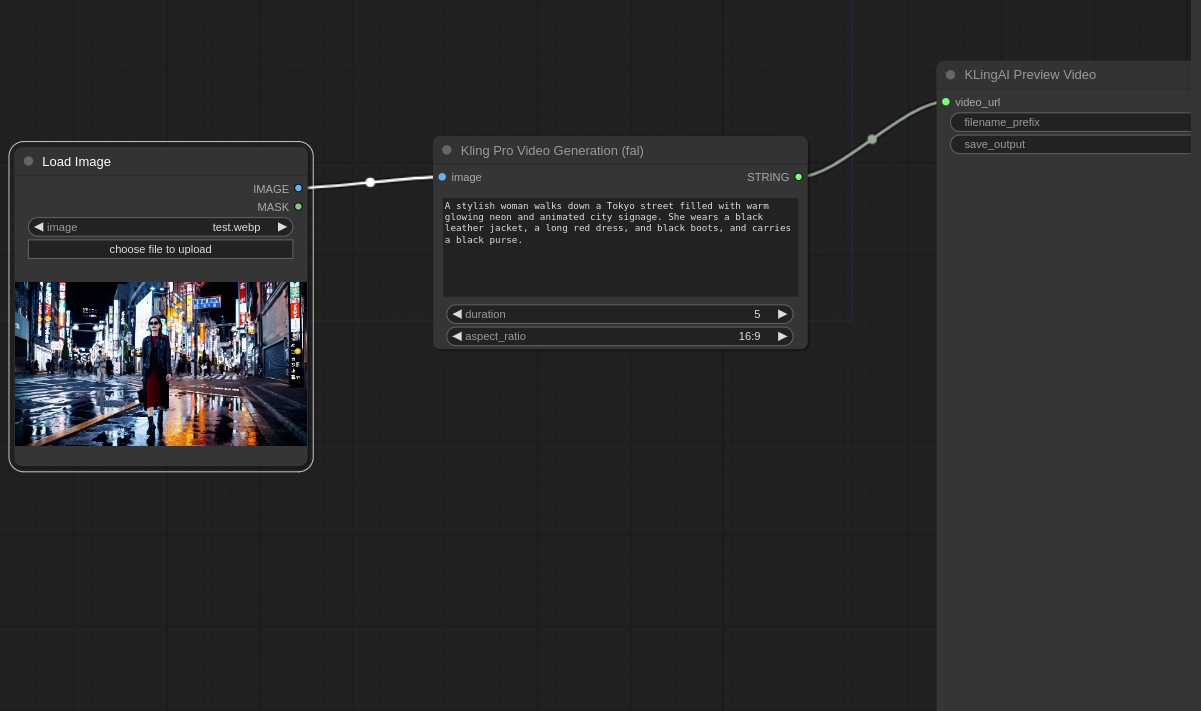
Attached is an example result from using the **Kling V1.5 Pro **model! 😉
November 28, 2024
🔧 What's New?
-
Supports new "Flux Tools" models - New Flux Diffusion and Controlnet models are now available on ThinkDiffusion.
- Fill (Inpainting) model - flux1-fill-dev.safetensors enables you to fill any details in a masked region.
- Redux - The flux1-redux-dev.safetensors is a model that can be used to prompt flux dev or flux schnell with one or more images.
- Canny and Depth - Depth offers stunning spatial accuracy and dynamic realism using depth maps, while Canny provides razor-sharp outlines with precise edge detection.
For workflows you can visit here
-
SD3.5 ControlNet Support – Stability has released official SD3.5 ControlNet models, now available on ThinkDiffusion.
Depth, Canny & Blur controlnet models are meant to be used with SD3.5 large.For workflow you can visit here
-
Support for LTX-Video Model – Create stunning video content effortlessly!
For workflows Click_Here
(Output attached below😉)
The latest ComfyUI version is now live under Beta-Version
🎥 Watch the overview by Sebastian Kamph here


November 19, 2024
Hey @everyone! Just a quick update today for those of you using Forge: We have updated Forge to the latest version which mainly includes fixes related to better memory management when switching models. What else?
Flux1-dev-bnb-nf4-v2is now available across all Forge versions.- Popular extensions such as Infinite Image Browser & Aspect Ratio are now preinstalled for your convenience.
- You can still add your own Extensions, LoRA's, Checkpoints, and more for enhanced customization!
The new Forge version is available under Beta-Version
November 13, 2024
Hey @everyone - this one is a bit long, but we have several exciting updates for you ComfyUI fans...
Why SD3.5?
- SD 3.5 Large: With 8 billion parameters, it offers superior quality and prompt adherence for pro-level creations at 1 MP resolution.
- SD 3.5 Medium: With 2.5 billion parameters, it delivers best-in-class image generation with advanced multi-resolution capabilities.
- SD 3.5 Large Turbo: Distilled, faster, and high-quality output in just 4 steps!
Highlights
Stable Diffusion 3.5 is packed with features that make it one of the most versatile and high-performing image models available, excelling in these key areas:
- Customizability: Fine-tune to fit your creative needs.
- Efficient Performance: Optimized for speed and quality.
- Diverse Outputs & Versatile Styles: Generate anything from 3D art and photography to line art with diverse representation!
Get Started with SD3.5
- SD3.5 models are preloaded in ComfyUI on ThinkDiffusion for your convenience.
- Try out the attached
sd3.5.jsonexample workflow from StabilityAI. - To run SD3.5 workflows, use our new ComfyUI Beta (Oct 24) releases
- Check out Sebastian Kamph's introduction video on SD3.5
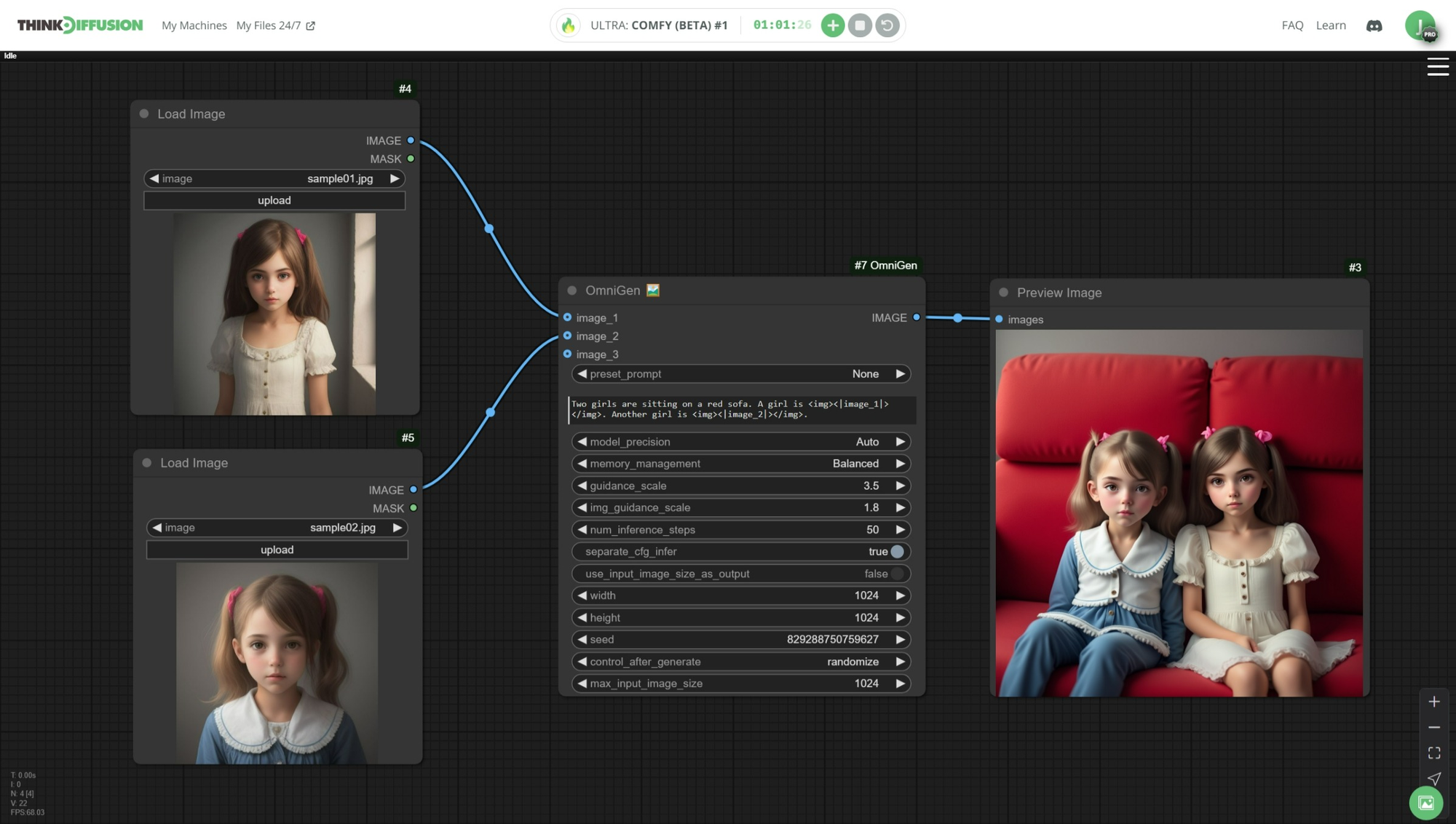
By popular demand, we've made sure Omnigen works on ThinkDiffusion:
- Run Omnigen on ComfyUI Current (Sept 24) and ComfyUI Beta (Oct 24) releases
- Get it running quickly with the workflow and sample images in the attached
td-omnigen.zipfile
- Get it running quickly with the workflow and sample images in the attached
- Things to note:
- The Omnigen node downloads the required model in real-time. Thus, after clicking
Generate, it may take around 10 minutes to download the model before the workflow continues. It may seem like the workflow isn't progressing, but it is—be patient, and it will complete. - The workflow requires a decent amount of RAM and will not work on
QUICKmachines. If switching from a heavy workflow, it's good toRESTARTComfyUI to release any consumed memory.
- The Omnigen node downloads the required model in real-time. Thus, after clicking
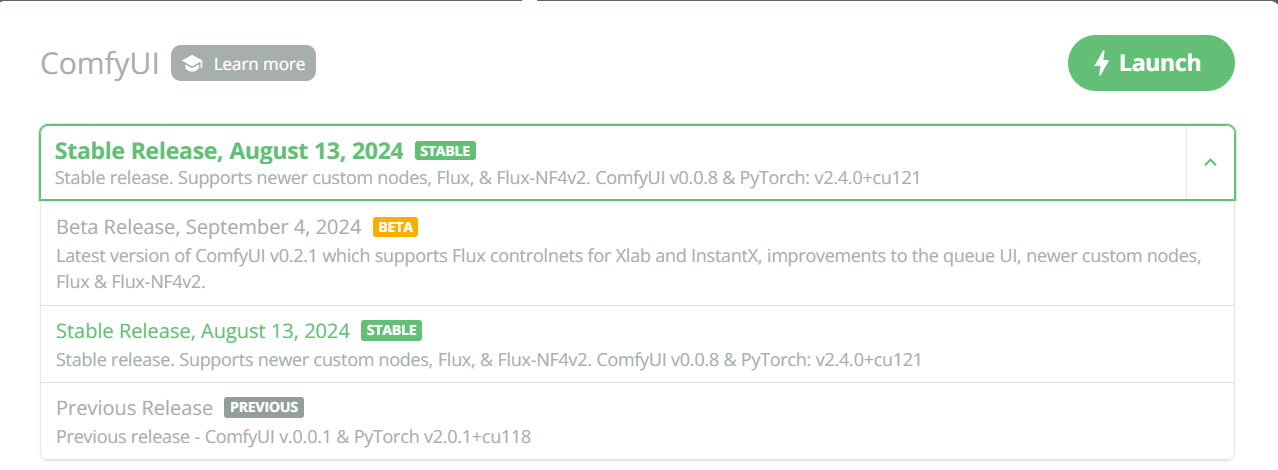
We've updated our ComfyUI versions with a new Beta version to support SD3.5. Additionally, all ComfyUI versions include performance fixes. Loading large models, such as Flux, should be noticeably faster (~2 mins instead of 10+ mins).
- ComfyUI Beta Release (Oct 24): ComfyUI v0.2.6 which supports SD3.5 and Omnigen
- ComfyUI Current Release (Sept 24): Previous
Betaversion now promoted to our currentStableversion; ComfyUI v0.2.1. Also supports Omnigen and includes performance fixes - ComfyUI Previous Release (Aug 13): The previous stable release in case an existing workflow is working on the new
Currentrelease
November 11, 2024
Helloooo @everyone ,
We're hosting another FLUX webinar with @Sebastian Kamph 🔥
Join us for 30 mins of "wait, you can do THAT?" moments as Sebastian deep-dives into 'AI Retouching with Flux Inpainting'.
Bring your images, your ideas, and your impossible wishes. Let's make them possible ✨
When?
20 November, 8 am PST.
Add to your calendar 👉 https://go.thinkdiffusion.com/fluxlive
October 16, 2024
What’s New in FaceFusion 3.0.0? 🎭
- Pixel Boost™ - Pixel upsampling for the face swappers.
- Multi Face Detector Angles - handles upside down faces.
- Face Editor - alter face expressions and even the head position.
- Expression Restorer - Live Portrait powered expression restorer processor.
🎥 Check out the trailer 👉 https://youtu.be/ZQ0xHU34okU?si=jT4ZVZiJd7noUoZW to see FaceFusion 3.0.0 in action!
Now Available:
FaceFusion 3.0.0 is available under the experimental section. Launch FaceFusion 3.0.0
🔗 For more information:
Check out the full release notes and details on project's github: https://github.com/facefusion/facefusion/releases/tag/3.0.0
Below is the example for Age-Modifier in Facefusion 3.0.0 👇
September 14, 2024
Hey @everyone how's it going!
We had a lot of requests coming in to host a session on FLUX We're stoked to announce our next webinar:
Intro to Flux & Stable Diffusion AMA with @Sebastian Kamph & @McShizzy
What?
Join us for a no-holds-barred Stable Diffusion AMA with Sebastian, a peek into the FLUX playground (bring your wildest ideas), and a live demo that'll make you go "How is this even possible?"
Whether you're an absolute beginner or seasoned pro, this is for you.
When?
25 September, 9 AM PST
Also snag a 50% off TD-Pro at the webinar!
Join us here - https://bit.ly/fluxwebina
September 5, 2024
@everyone - super short update... You may have noticed that we've made what we shifted the ComfyUI versions. What was previously the Beta version with Flux support is now the current Stable Release. We also published a new Beta version where users can test out the latest release of ComfyUI
September 3, 2024
hi @everyone! I have just a quick update today for those of you using ComfyUI and are fans of RgThree
We fixed the RgThree issue crashing and showing Running... in another tab in the progress bar.
- We had a workaround by preinstalling a version that worked but it was limited to an outdated version of RgThree.
- Now RgThree is no longer preinstalled - if you love it like I do, then you will need to install it
- The upside to this is that you can always update to the latest version of RgThree and avail yourself to it's latest features without issue.
Don't know what RgThree is? It has a bunch of useful nodes and UI enhancements such as a top level overall and node-specific progress bar. Check them out at https://github.com/rgthree/rgthree-comfy
That's it for now. Happy creating!
August 28, 2024
Here's another quick announcement @everyone
...Try Forge
Flux is still all the rave. While it's still not supported on Automatic1111, it is supported on Forge, and we just released Forge under Experimental apps: https://www.thinkdiffusion.com/select-machine/experimental/forge. If you're not familiar with Forge, it was developed by the same creator of Fooocus and IC-Light. Forge was created from a fork of Automatic1111 so users who use Automatic1111 should feel comfortable with its UI. Its purpose is to "to make development easier, optimize resource management, speed up inference, and study experimental features."
- Try out Forge out here: https://www.thinkdiffusion.com/select-machine/experimental/forge
- To try out Flux, you will need to install the NF4 version of the Flux model into the
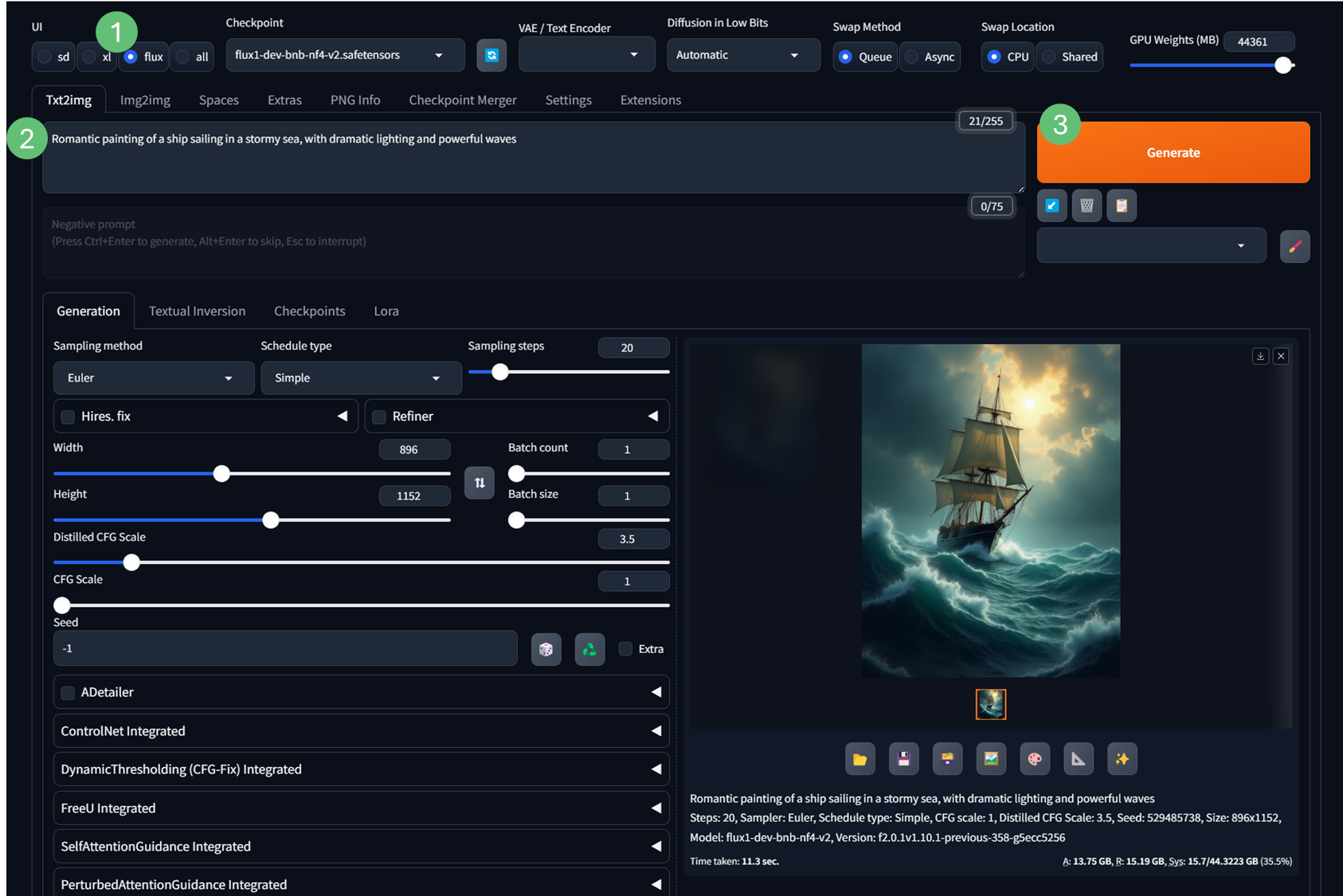
/forge/models/Stable-diffusion/folder: https://huggingface.co/lllyasviel/flux1-dev-bnb-nf4/tree/main - Using it is easy (see screenshot):
- Just select
Fluxas theUIand Forge will automatically configure the UI with defaults for Flux. - Select your Flux model and Enter your prompt
- Generate!
Note the Flux model can take some time to load into memory on your first Generation since it's such a large model so be patient - it's working.
- Just select
- To try out Flux, you will need to install the NF4 version of the Flux model into the

Find out more from the project's github: https://github.com/lllyasviel/stable-diffusion-webui-forge
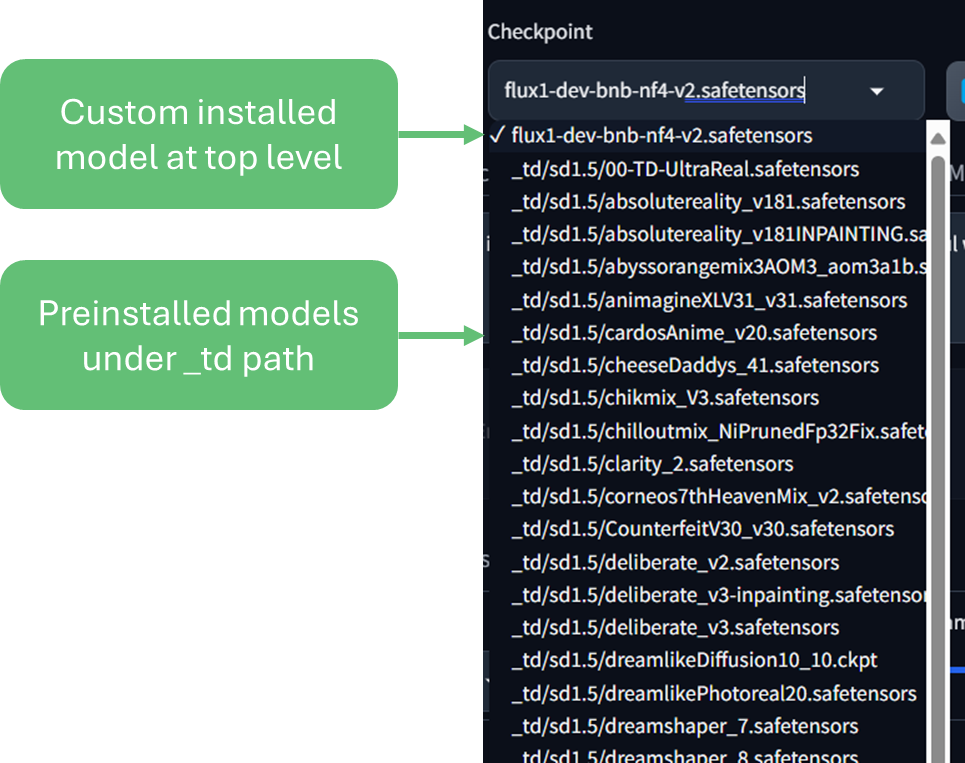
By request, we've grouped all the preinstalled checkpoints under a _td folder. This way when you upload your own models, they can easily be recognized separately from our preinstalled ones. Note: this may mean existing workflows that pointed to a preinstalled model may error as the model has moved. Simply select the correct model from the new folder structure.
August 22, 2024
Hi @everyone!
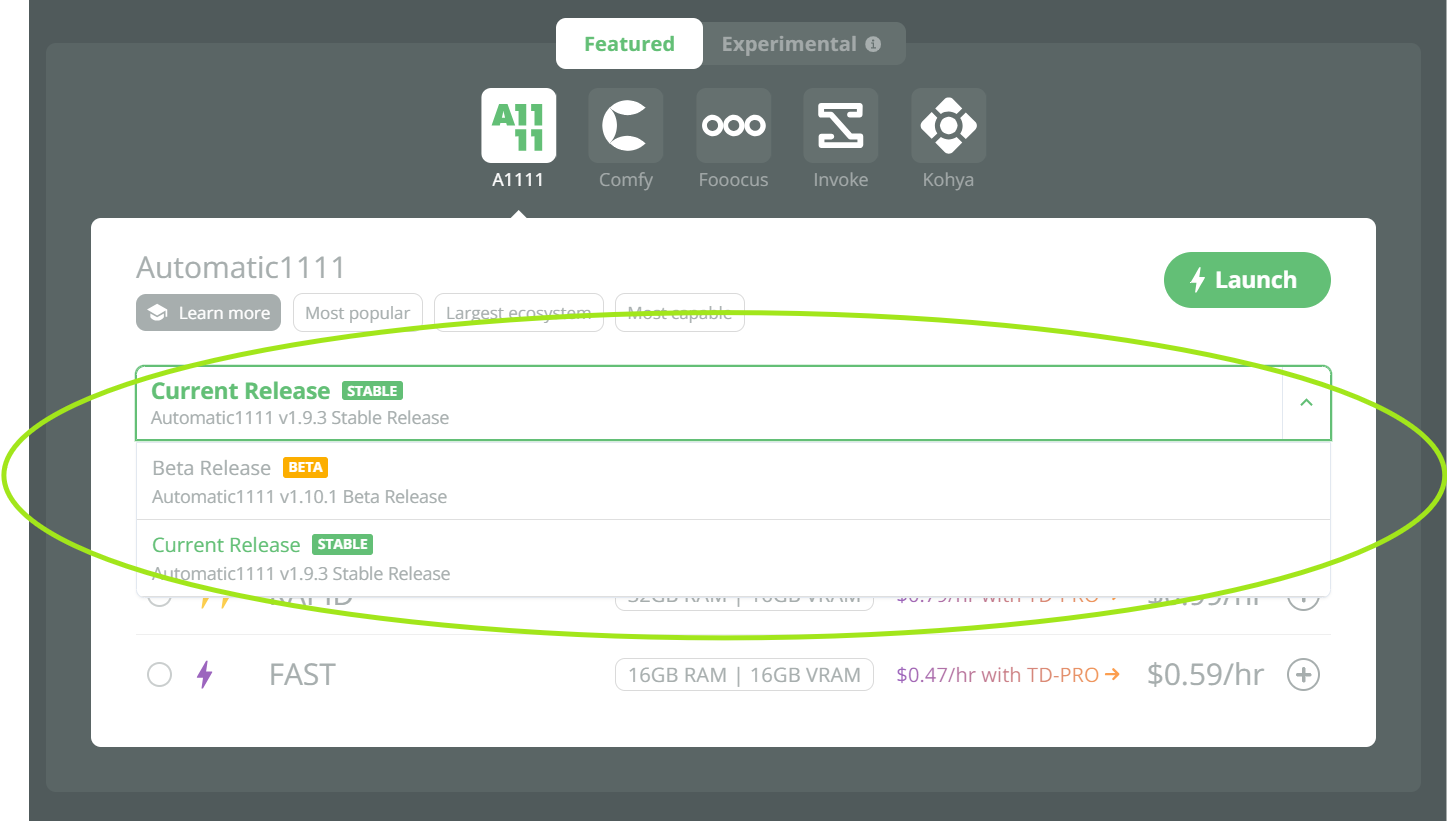
You may have noticed, we've updated ThinkDiffusion's UI for selecting machines to support multiple versions of apps.
- This will allow us to more quickly make available machines with latest features that may still be in beta.
- Simply select your App and if there are multiple versions available, you will see a
Versiondropdown - We temporarily had a few of these for Automatic1111 and ComfyUI under the
Experimentalapps so if you were using it there, it's not gone - it's just moved.
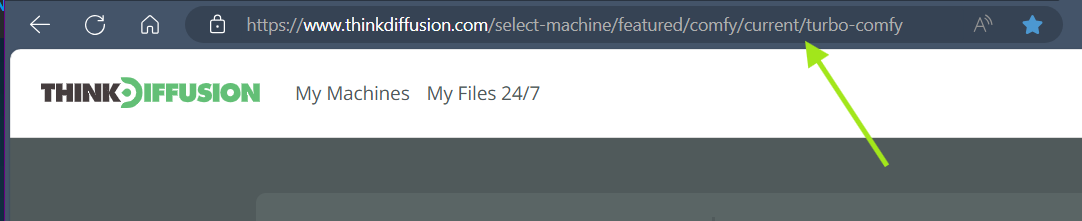
We now manage navigating to machine via the URL. Whenever you switch machines, you will see the URL path update correspondingly. Now you can quickly navigate to your favorite machine by simply bookmarking the page.
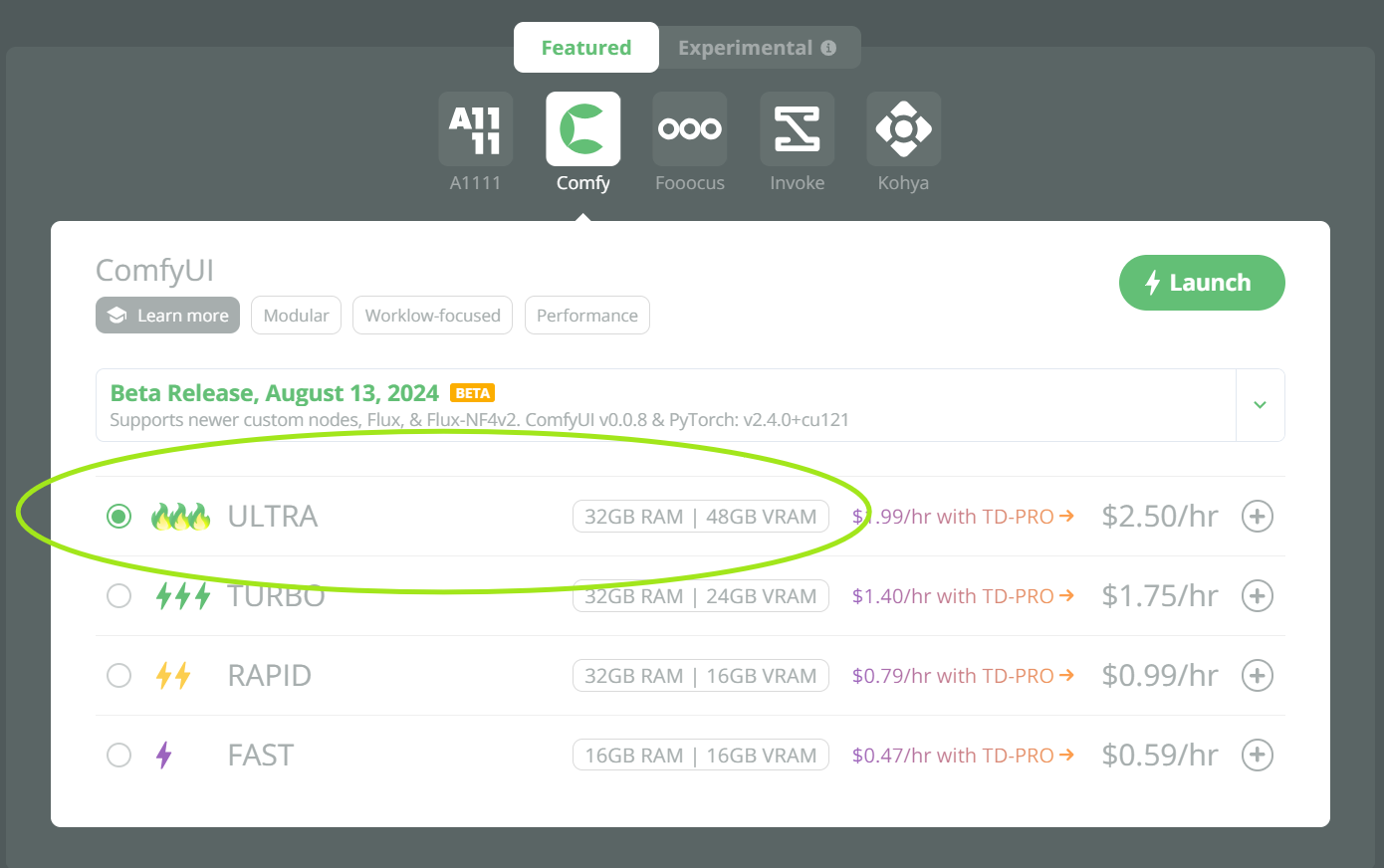
Got some memory-intensive ComfyUI workflows - we now have 48GB VRAM machines! Check out Comfy ULTRA machine and get around your out-of-memory issues: https://www.thinkdiffusion.com/select-machine/featured/comfy/beta/ultra-comfy-beta We'll be rolling out more ULTRA machines for other apps so keep an eye out for them.
August 14, 2024
Hey @everyone Excited to announce that FLUX & Flux-NF4 is now available on Experimental-ComfyUI! What makes FLUX so special?
- Better image quality: FLUX is relatively better in generating human figures, particularly hands and other features.
- Better prompt readability: FLUX is really good at handling challenging words and repeated letters effortlessly, delivering accurate results from detailed prompts.
- Optimized Performance: The dev and schnell variants of FLUX delivers improved efficiency in both size and speed, enabling better image quality.
What's Included?
- All flux NF4, vae & dev models are preloaded.
- Preloaded custom node supporting Flux.
And not only FLUX, Experimental-ComfyUI offers:
- Support to newer custom nodes.
- PyTorch: 2.4.0+cu121
- Cuda: 12.1
- ComfyUI Release: v 0.0.8(August 13 2024)
Checkout this tutorial for FLUX - https://youtu.be/3kljJNosQ1I?si=T5cRIrQj5mBc9Dzv
Here are few easy to start Flux workflows(Available on Github):
Note: Fp8 & Fp16 workflows works with flux1-dev.sft model as well
Where to find new experimental comfy app? Check screenshot...
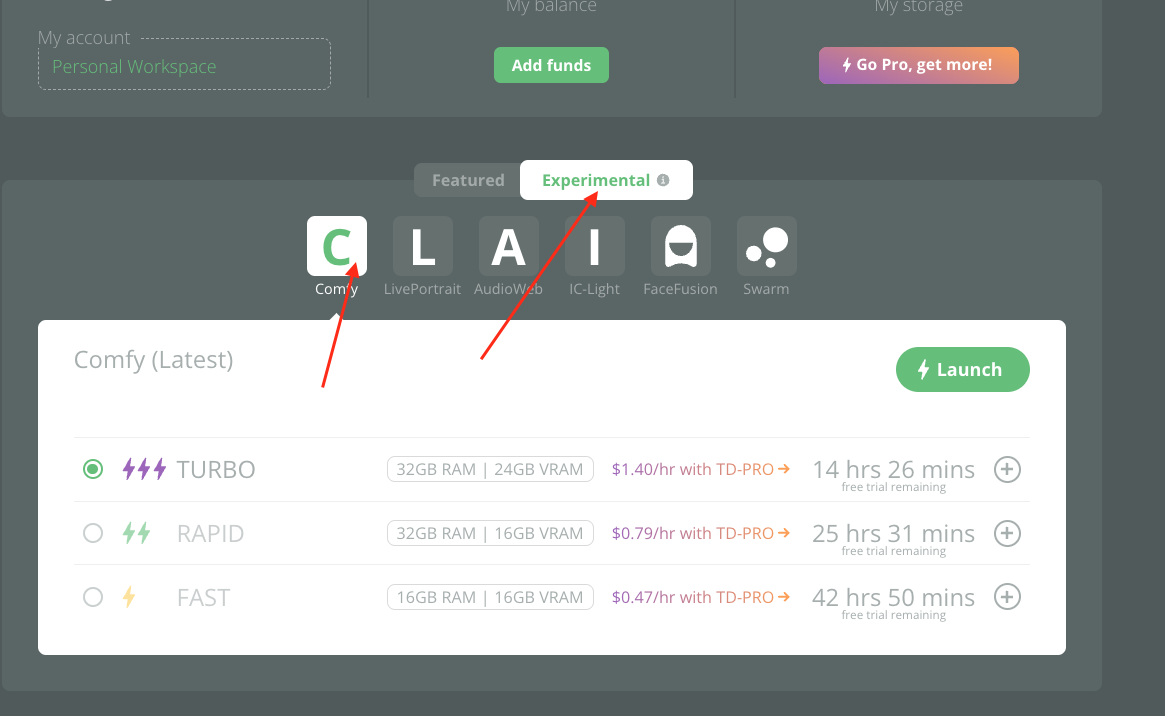
August 7, 2024
Hey @everyone. Ever wondered how it would feel to transform your voice into another character, have your text read aloud by a voice you love, or even create your own AI-generated music?
Look no further, Audio-WebUI is here to make it all possible!
Features:
- Text to Speech: Convert your text into lifelike speech using a variety of voices. There are some preloaded voices with different accents for you to try out.
- Voice Transformation: Transform your voice into any character you desire.
- AI Music Creation: Even if you don't know much about musical tools, you can create some cool AI-generated music in genres like classical, jazz, rock, and more just by writing a prompt.
- Speech to Text: Convert any spoken words into texts easily.
And that’s not all! There are many other features for you to explore on Audio-WebUI. For more information checkout Audio-WebUI.
For a quick tutorial - https://youtu.be/r5pu-oeIfMY?si=V5ffgui3h-ySGApX&t=265
Now available under experimental apps. Launch Audio-WebUI!
July 18, 2024
Hey @everyone,
We 're thrilled to introduce you to LivePortrait – a fascinating tool that brings your portraits to life! 🖼️✨
Check it out under the Experirmental apps: https://www.thinkdiffusion.com/select-machine/liveportrait
What is Live Portrait?
As the name suggests, your portrait will come to life. Simply upload a single picture that you want to animate and a video containing facial expressions, and Live Portrait AI will combine them into a video of your picture animated with the facial expressions!
🎥➡️🖼️
Why Use Live Portrait?
- Easy to Use: Just upload your picture and video, and let LivePortrait work its magic.
- Adjustable Eye & Lip Size: You can even adjust the eye size & lip size of the image to achieve the perfect look!
- Interactive Examples: Live Portrait comes with several pre-uploaded examples. You can simply choose these examples to see the tool in action and get a feel for its capabilities.
Get more info and see examples on LivePortrait's repository
June 19, 2024
New IC-Light Machines (Experimental)
We said we wanted to get out apps faster with the new experimental section (📢-announcements) so check out IC-Light machines we just released.
This is the best background removal and replacement tool. The key is to get the lighting, reflections, and shadows right on your subject based on the new surroundings. Create the perfect mood and setting for your images. Just upload your subject's photo, specify the lighting conditions in the prompt, and watch the magic happen.
Many examples provided by the creator: https://github.com/lllyasviel/IC-Light?tab=readme-ov-file#screenshot
As always, we're excited to see what you create!
Note: Images on IC-Light machines will not be saved to your cloud storage. To save the image, right-click on the image and use "Save image as" to download it to your local computer.
June 18, 2024
Hello TD fans (@everyone),
Experimental Apps:
We're excited to announce a new section for Experimental apps. While the apps may not be fully vetted, the experimental section will get you access to the latest and most trending apps as soon as possible.
Have fun discovering and exploring new apps - just note that support for these experimental apps may be limited as we may not know all their nooks and crannies.
Improved Design
To make our life harder (and yours easier), we decided to redesign the entire /select-machine page Less scrolling and clicks for your most common actions. We hope you like the new design as much as we do! (edited)
June 10, 2024
what's up @everyone
Please join ThinkDiffusion for the first Project Odyssey AI Filmmaking Competition from June 17th to July 15th!
We are super proud to be partnering with Civitai, 11Elevenlabs, and Realdreams, with a great group of sponsors as well and over $28K in cash, credits and prizes.
As one of the founding organizers, we're excited to challenge our community to make next-level 3D Animations, Music Videos, Narrative Shorts, and more. Sign up at: https://projectodyssey.ai/
We also have an Exclusive one-time promotion for 50% off for the 1st month of TD-Pro for new TD-Pro Subscribers., check out here for more details! https://go.thinkdiffusion.com/ody-d
Can't wait to see what y'all make!! keep us posted, share what you got, and let us know if you need any questions or help. Cheers!
May 15, 2024
Hi everyone,
If your generated image doesn't match your model's expectations, there might be a bug related to the Automatic1111 v1.9 upgrade on our machines. We have fixed this issue, but you may need to take action to fully apply the fix. This bug affects all A1111 machines - FAST, RAPID, and TURBO.
Issue: The model displayed when launching a new A1111 machine might not be the actual model loaded, resulting in images being generated from a different model than what the UI shows.
Note: This bug does not affect new users or users who never changed the model from the TD default model.
Root Cause: When selecting a new checkpoint/model, Automatic1111 would calculate the hash of the file and append it to the name of the checkpoint/model in a1111/configs/config.json e.g. _sdxl/ThinkDiffusionXL.safetensors [a21c9949ef]
However, when starting a new machine, Automatic1111 would not find the file with the given name with hash included, causing it to revert back to a fallback checkpoint 01-sd_xl_base_1.0.safetensors without showing the fallback model in the UI.
Our Fix: A1111 apps has been updated with the --no-hashing option, so the hash will no longer be calculated and appended to the model name.
(YOUR) USER ACTION MAY BE REQUIRED To fully apply the fix, you need select a different model then load any model of your choice.
May 13, 2024
Hey everyone!!!
We've just rolled out a major update for ComfyUI machines that now allows models to persist when installed via the ComfyUI Manager.
Previously, model files would only persist if you uploaded them through the ThinkDiffusion file browser.
What does this mean going forward?
- Any models added through ComfyUI Manager are persistent across sessions.
- Model sub-directories will be located at
comfyui/models, as specified natively by the ComfyUI Manager. - You can download models directly from the ComfyUI Manager. (You can still use the ThinkDiffusion file browser as well.)
Note: Temporarily, you may see multiple model folders with similar names such as Lora & loras. We will be cleaning up the duplicate old directory names and keeping the folders that are natively created by the ComfyUI Manager.
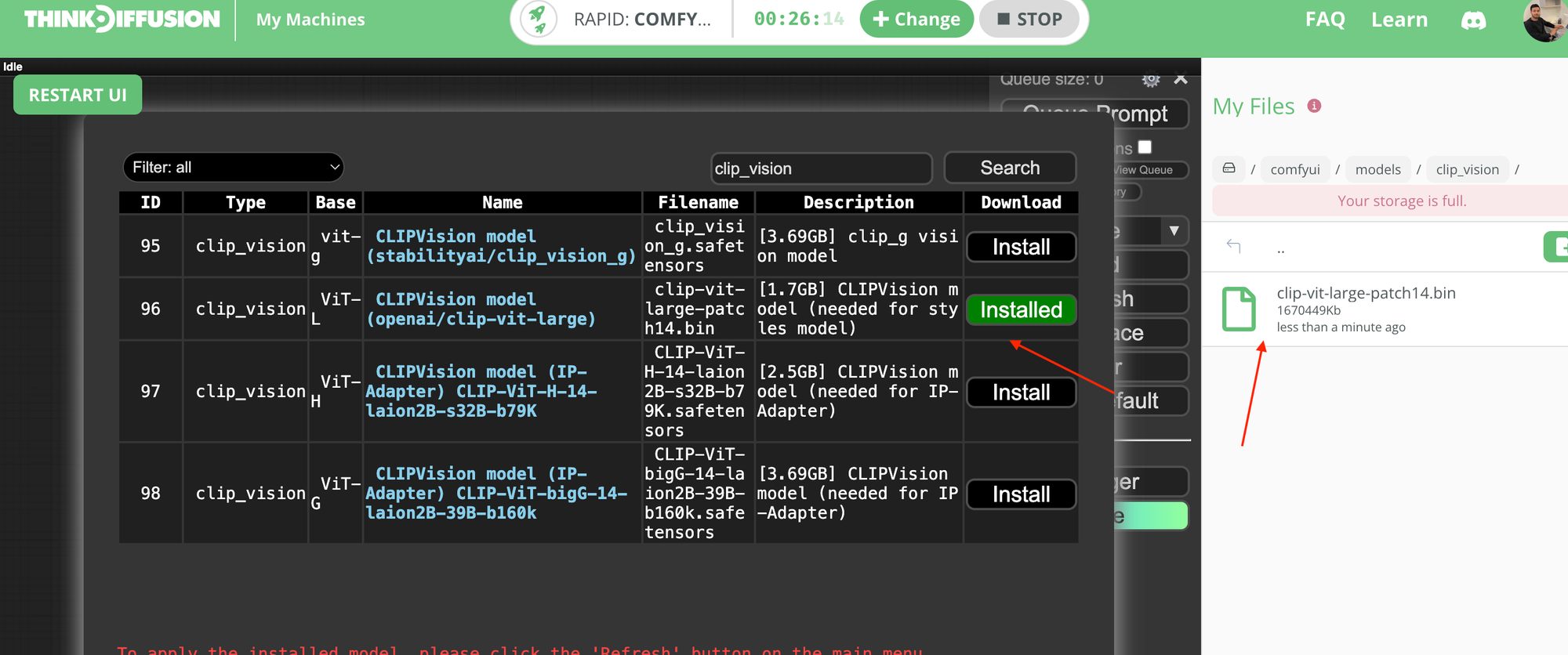
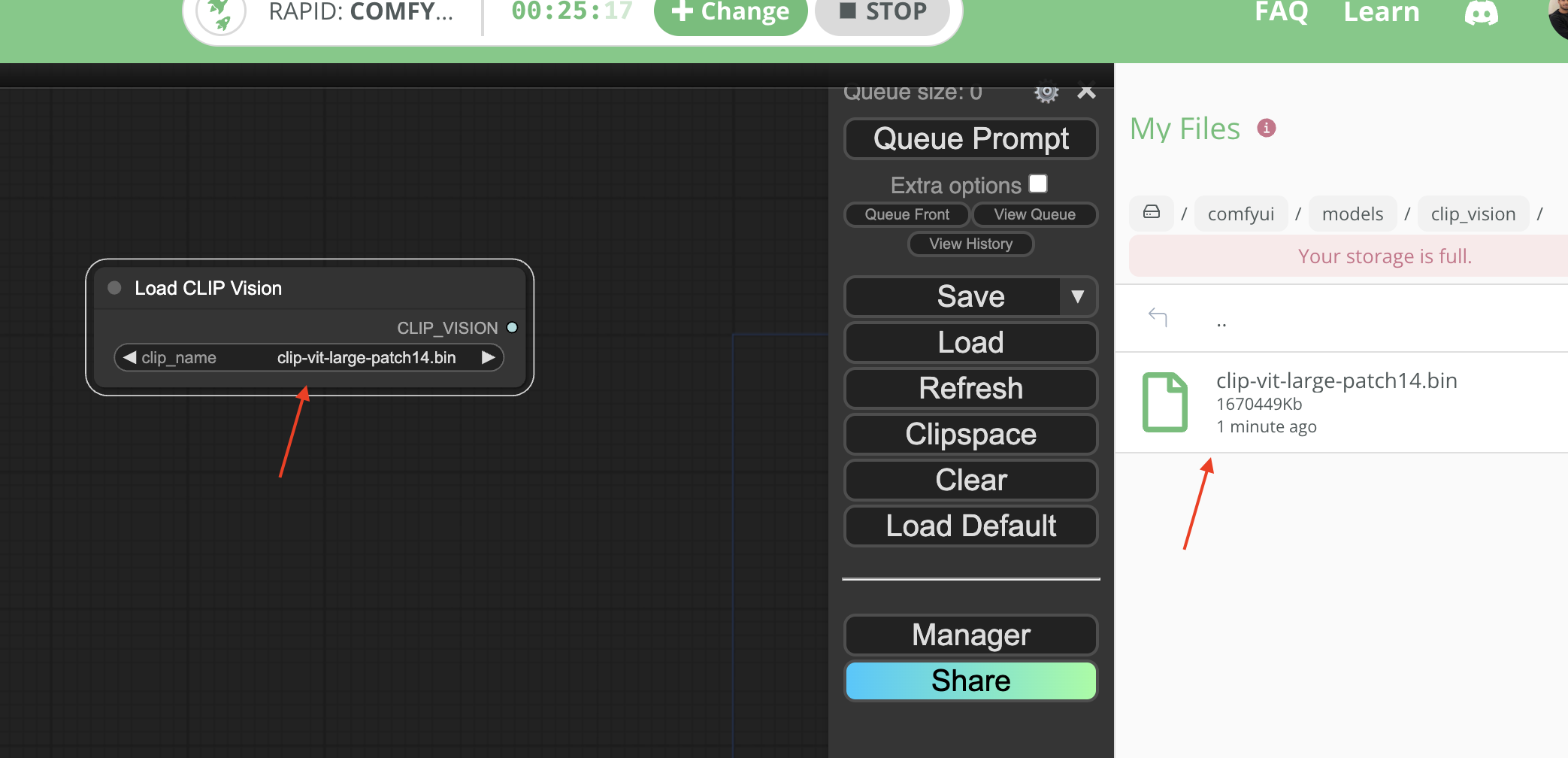
April 23, 2024
Hey TD Fam! 🚀 Exciting news ahead! 🎉
We're thrilled to announce that our Automatic1111 machines are now upgraded to the latest release v1.9.3. 🌟
To get all the information regarding fixed packages and new updates, check out the updated change log: https://github.com/AUTOMATIC1111/stable-diffusion-webui/releases/tag/v1.9.3 💫
With this upgrade to A1111 v1.93, we bid farewell to Sadtalker due to compatibility issues. While we're sad to Sadtalker go 🙄, we recommend using Wav2Lip and FaceFusion’s lip_syncer 🗣️ which have improved functionality for syncing lips to audio clips.
April 18, 2024
Sending positivity your way! Hope you’re all doing amazing.
We’ve heard your calls and we’re super excited to announce that StableSwarmUI is now part of our ThinkDiffusion platform. StableSwarmUI is
A Modular Stable Diffusion Web-User-Interface, with an emphasis on making powertools easily accessible, high performance, and extensibility.
- Run multiple apps together: StableSwarmUI brings capabilities from your favorite StableDiffusion UIs, ComfyUI and Automatic1111, together in a single interface allowing you to quickly switch between A1111-like image generation or complex ComfyUI workflows.
- Effortless Browsing: StableSwarmUI provides a clean interface to quickly browse recently generated creations, all organized for easy viewing.
- Smart compatibility checks: StableSwarmUI detects if LoRAs and ControlNets are compatible with your selected model. If they're not compatible, they fade out and move to the bottom of the list.
- Workflow management: Quickly save, load, and organize your ComfyUI workflows. Use StableSwarmUI's grid view to easily compare and manage your workflows.
- Simple batch editing: No more hassle to import many images as StableSwarmUI can edit a batch of images in a single go with the help of Image edit batcher.
- Clear debugging: StableSwarmUI keeps you informed with well-organized and categorized logs. Warning and error logs for all connected backend services are easily identifiable.
- Multi-Language Support:StableSwarmUI allows you to work in your preferred language.
Here is a cool guide by Sebastian Kamph on how to get started with SwarnUI
We have recently partnered with FaceFusion to bring exclusive green edition with TD only exclusive features.
- Everything included in FaceFusion v2.5.0
- TD custom Green Theme
- No more donate button
- New ghost swappers models & many more models.
- Specifically optimized for ThinkDiffusion.
- Direct support for TD users now available FaceFusion's Discord #thinkdiffusion channel
- Check the #changelog channel on FaceFusion's Discord to see what's updated in v2.5.0
April 10, 2024
There have been many requests for saving/loading workflows directly to machine file browser, so we have introduced a new feature, which lets you keep/load all your workflows under comfyui/workflows.
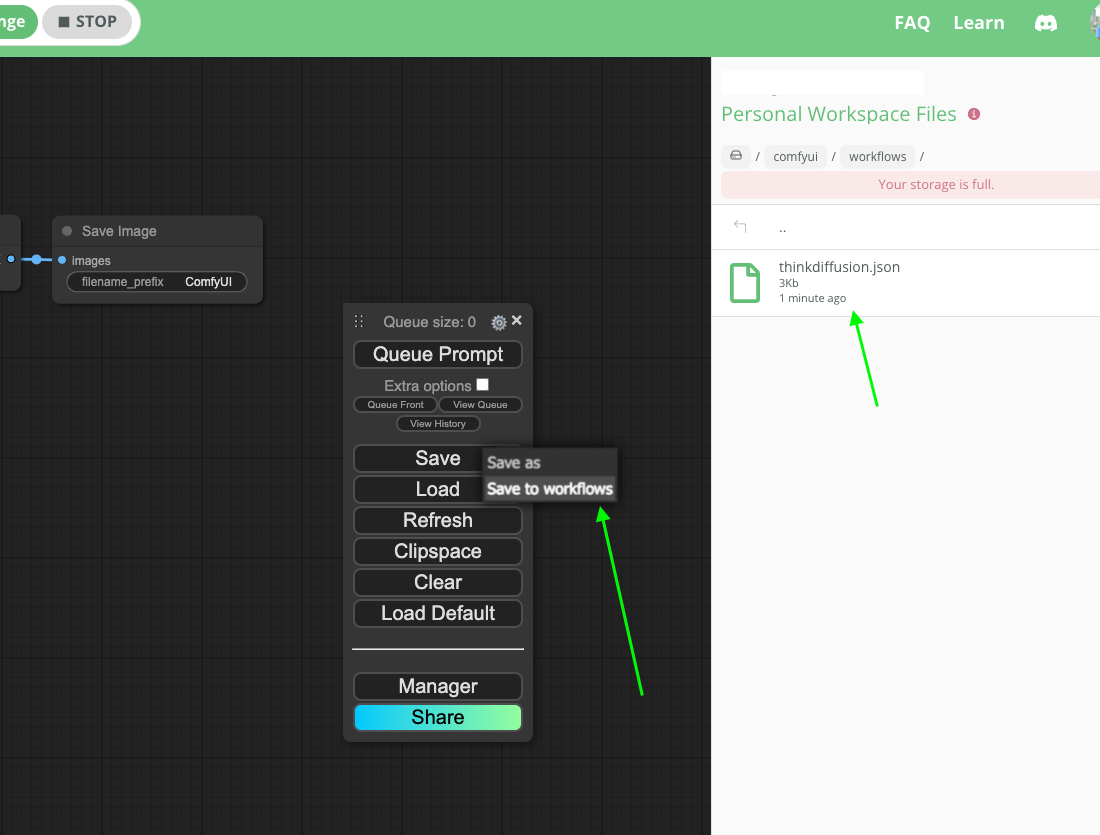
How to save workflows in file browser
To save current workflow into Thinkdiffusion file browser, you can click on the save dropdown(as shown in the screenshot below) & click on Save to workflows, saved workflow can be found inside comfyui/workflows.
✅ Saved workflows are persistent between your sessions.
How to load saved workflows
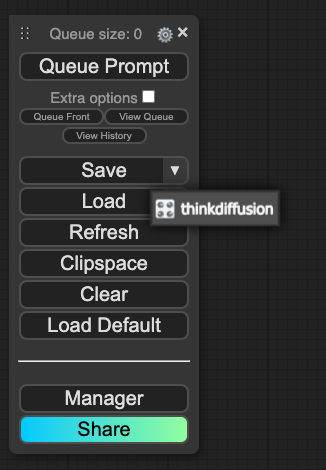
To load any previously saved workflows, you can click on the Load dropdown & you will see a list of all saved workflows.
Click on the workflow name & your workflow will be loaded into Editor area.
What's 💫 new in ComfyUI?
ComfyUI & ComfyUI Manager has been updated to the latest versions.
All preloaded custom nodes are updated.
Pip packages are preloaded to fix issues with KJNodes, ComfyUI-Impact-Pack, SUPIR, ComfyUI-Crystools & FizzyNodes.
Minor bug fixes.
New model mapping is available to support IPAdapter models, user can now upload your IPAdapter models into comfyui/models/ipadapter.
Feel free suggest any similar cool features. Please report any bugs through #🔧-help-desk channel.
March 20, 2024
Hey @everyone! I hope you're all enjoying the wonderful spring season. 🍃 🌸
I am happy to share an exciting news with you. As a sense of great demand for face swap, we are happy to integrate FaceFusion app into ThinkDiffusion platform.
FaceFusion is an open source face swap & face enhancer tool helps you to swap/enhance faces given any image or video. It comes with preloaded face swap models, automatic face detection, swap & enhancement controls.
What's cool about FaceFusion?
- Effortless Face Swapping: Put your face on celebrities, historical figures, or even animals. Facefusion's advanced technology makes it seamless.
- Swap Multiple Faces: Select multiple faces references & swap them based on their order.
- Face Swap Controls: Configure mask blur, mask padding, age, gender & order analysis.
- Quick & Easy: Fast & Simple face swapping with quick results.
How to use?
Here is a cool video by Sebastian Kamph on how to use Facefusion:
We're also excited to share that we're planning to add even more amazing features soon, so stay tuned! ⚡
ComfyUI & Manager has been updated to the latest version.
All preloaded custom nodes are updated e.g. AnimateDiff, VideoHelperSuite, Controlnet etc.
Support for ComfyUI Inpaint Node
Github: https://github.com/Acly/comfyui-inpaint-nodes
Shoutout to @OJ Faker , We have added model mapping for ComfyUI/models/inpaint to support inpainting.
February 28, 2024
Hi, TD Friends! Good news keeps coming!
At the request of many of you, we have added an option for unzipping files. It's currently only available on the 24/7 File Browser, but we'll be adding this long-requested feature to the In-Machine file browser in the next few days!
The usage is pretty straightforward: For any zip file in your file browser, just click the "More options" button, and you'll see two different unzip buttons:
- Unzip to current folder will extract the contents of the zip file in the current folder.
- Unzip into "/zip_file_name" will create a folder with the same name as the zip file, and the zip contents will be extracted inside.
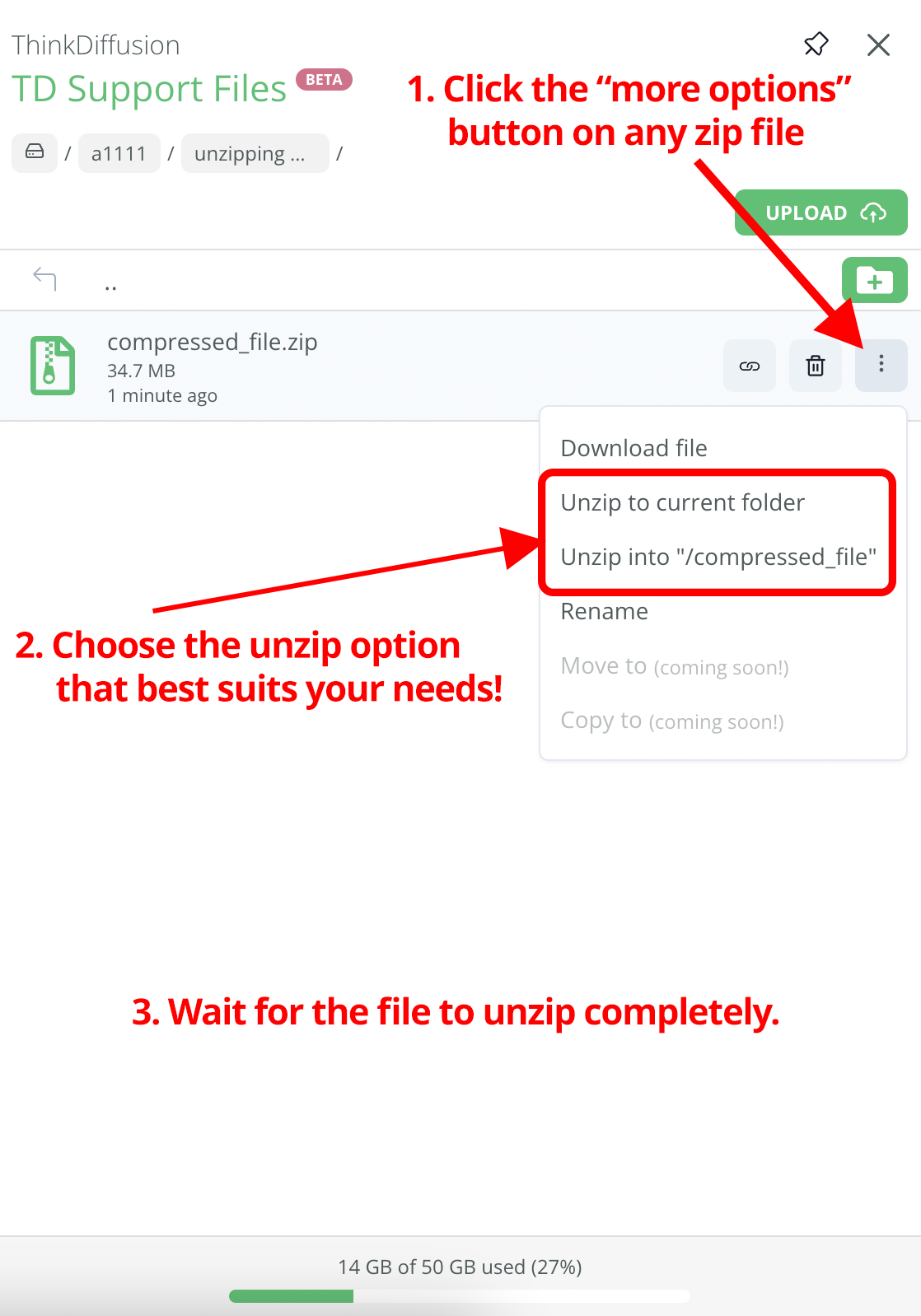
Take note that this is an early version, so unzipping progress in not being tracked yet. We'll be adding this feature soon.
We'll be glad to hear your feedback!
February 20, 2024
Hi TD Friends!
Looks like we have some back-to-back great news...
For all of us newbies to the AI Art world and stable-diffusion, check out yesterday's announcement about our new Beginner’s Course to Stable Diffusion . It's free so enroll now!
And now, by popular-demand, we present to you TD-Teams ! https://www.thinkdiffusion.com/pricing#teams
With TD-Teams, members can work together seamlessly within dedicated workspaces, each designed to streamline collaboration on distinct projects, workflows, or client engagements. Share models, settings, and files in independent workspaces, each with their own dedicated file system.
TD-Teams is in Beta which just means we have lots more features planned and in development for it. With this initial release you have all the core features to collaborate with your team members on multiple projects:
- 20% discounted rate on all machines
- $20 balance credit every month
- Includes 2 team members and a 200 GB default Teams workspace
- Add up to 18 more Team Members for a total of 20 for just $6/member/mo
- Add as many workspaces as you need.
- Small (50 GB): $10/mo
- Medium (100 GB): $15/mo
- Large (200 GB): $20/mo
- Manage team member access to each workspace according to your collaboration needs
- Persistent storage for life of plan on all workspaces
- My Files 24/7: manage files anytime for free without launching a machine
- Priority Support; video calls with in-house experts
As always, reach out to us with any questions.
February 19, 2024
@everyone
In recent months, we've received numerous inquiries from newcomers about how to get started with Stable Diffusion on ThinkDiffusion. In response, we've teamed up with Sebastian Kamph to introduce the "Beginner's Course to Stable Diffusion."
Check it out on our freshly minted Learn page: https://www.thinkdiffusion.com/learn
This course unfolds across 7 concise sections, taking you through the essentials of image generation, explaining those tricky acronyms, and concluding with a sweet guide on leveraging ControlNet to turn sketches to masterpieces. And guess what? If you dare to complete it, you'll earn a spiffy certificate to flaunt in front of all the newcomers
Cheers,
Phu
February 8, 2024
Hello everybody!
As you may have noticed, output folders cannot be deleted because this can cause errors in the operation of Stable Diffusion. For this reason, we have recently received many requests from you to empty the outputs folder to free up some of your storage space.
Today we have rolled out a small update to both File Browsers so you can clear out your outputs folders whenever you want!
Please note that this action is irreversible and we cannot recover your files once deleted!
The operation is similar in both File Browsers, but the button to clear out the outputs folders is located in different places. You can see where to find the button in each File Browser in the attached screenshots.
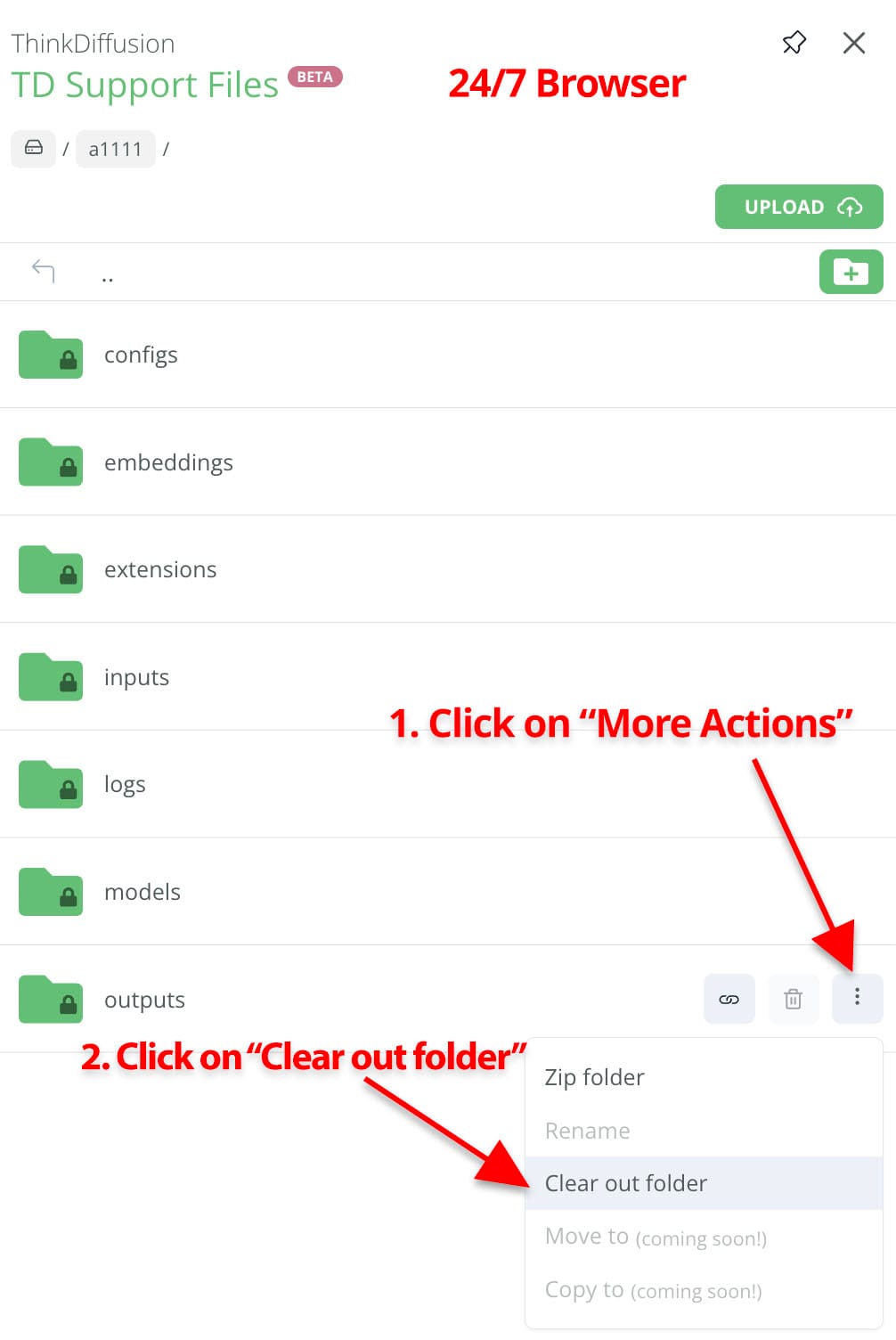
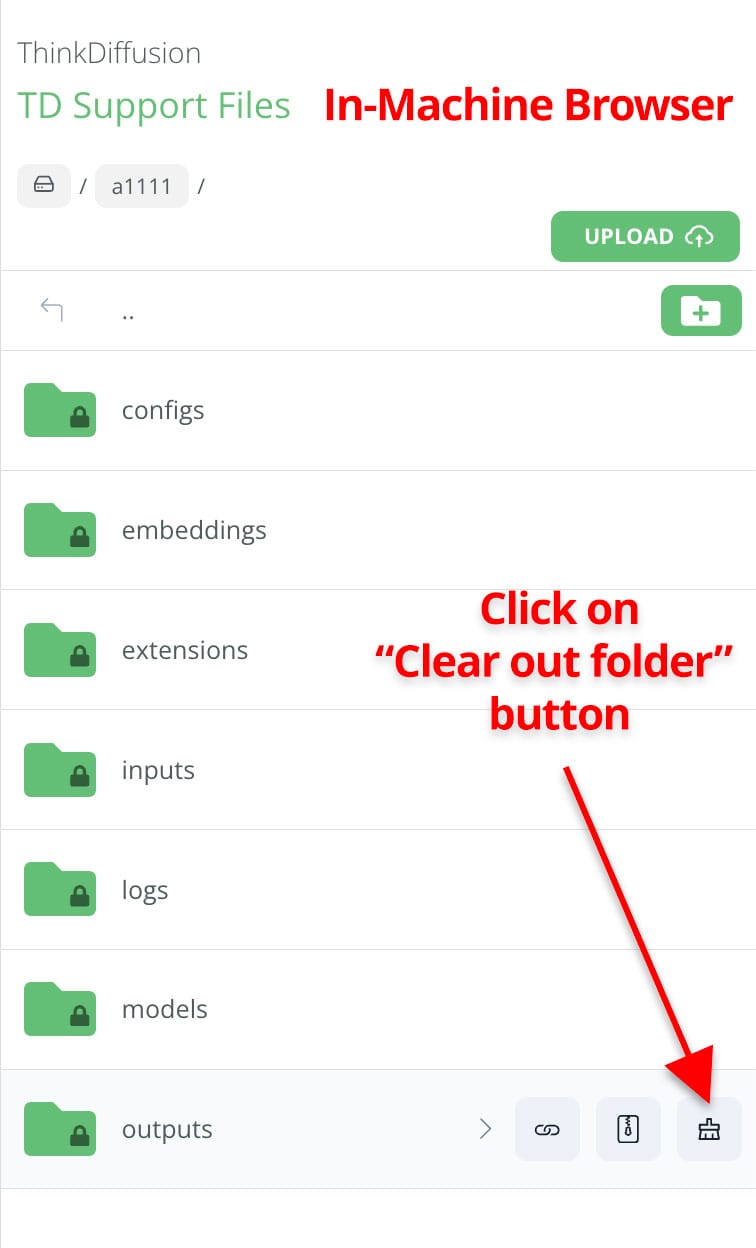
Cheers!
February 5, 2024
Quick update,
Recently, there's been an increase of new users, who after installing incompatible extensions, causes their A1111 machines to fail to launch. This left users unable to access their A1111 to uninstall the problematic extension.
Some resourceful users found a workaround by using applications like Fooocus to access the file browser. They would then delete all files in the a1111/configs/ and a1111/extensions/ directories, effectively resetting their A1111 instance to its default settings, which resolved the issue upon the next launch. (BTW if you're a TD-Pro member you can always access your files with My Files 24/7 without launching a machine)
Now you no longer need to resort to such measures for a fresh start on your A1111 or ComfyUI instances. We've introduced a "Reset to Default" button in the right-hand side panel, allowing you to easily reset your A1111 or ComfyUI back to the default ThinkDiffusion settings.
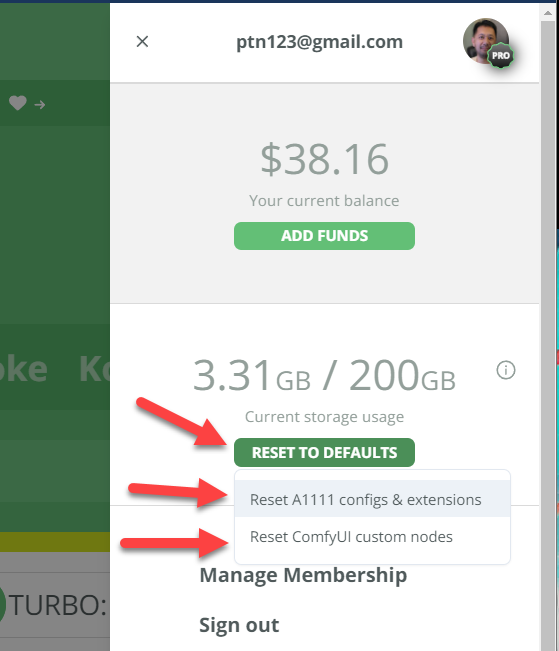
Cheers
Member discussion