

Prompt: A male assassin dances fluidly atop a city rooftop at night, full dark robe attire blending modern tactical gear with elegant, flowing elements. Neon lights from the city skyline reflect off his outfit as he moves with precision and grace, his silhouette striking against the urban backdrop.
Tired of dealing with complex setups and high memory demands just to make a single video? WAN2.2 Rapid-AllInOne changes the game by combining the best of WAN 2.2 and its accelerators into one lightweight, user-friendly model that works fast—even on lower VRAM systems.
Making AI videos usually means downloading multiple huge model files, dealing with memory errors, and babysitting complicated setups. WAN 2.2 Rapid-AllInOne rolls everything into a single file that runs faster and needs less VRAM.
It combines WAN 2.2, its accelerators, CLIP, and VAE into one model created by Phr00t. You load one file instead of several, it runs in 4 sampling steps, and works on lower-end hardware. Whether you're starting from an image or a text prompt, you get smooth motion without the usual technical headaches.
What we'll cover:
- Why this model is easier than regular WAN 2.2
- How to install and set up the workflow
- Running different generation modes (image-to-video, text-to-video, etc.)
- Examples and troubleshooting
Why Use Wan 2.2 Rapid-AllInOne?
Prompt: A toy vehicle sits on a polished wooden tabletop, captured from a dramatic front-facing perspective. Suddenly, a pair of playful child’s fingers gently grasp the miniature vehicle and rotate it, revealing its detailed rear view.
Rapid-AllInOne is a fast, all-in-one AI video generation model developed by the creator “Phr00t,” who merged WAN 2.2 and various accelerators, along with CLIP and VAE, to deliver rapid, simplified video creation for image-to-video and text-to-video workflows. Its standout features are single-file convenience, suitable for low VRAM usage, and native integration of CLIP, VAE, and WAN accelerators for high performance and flexible output. The model is designed for speed, requiring only 4 sampling steps and 1 CFG, supporting dynamic tasks like last-frame and first-to-last-frame generation while ensuring compatibility with both WAN 2.1 and 2.2 LORAs.
Download Workflow
Installation guide
- Download the workflow file
- Open ComfyUI (local or ThinkDiffusion)
- Drag the workflow file into the ComfyUI window
- If you see red nodes, install missing components:
- ComfyUI Manager > Install Missing Custom Nodes
Verified to work on ThinkDiffusion Build: September 5, 2025
ComfyUI v0.3.57 with the use wan2.2-rapid-mega-aio-v1.safetensors
model support
Minimum Machine Size: Turbo
Use the specified machine size or higher to ensure it meets the VRAM and performance requirements of the workflow
Custom Nodes
If there are red nodes in the workflow, it means that the workflow lacks the certain required nodes. Install the custom nodes in order for the workflow to work.
- Go to the ComfyUI Manager > Click Install Missing Custom Nodes
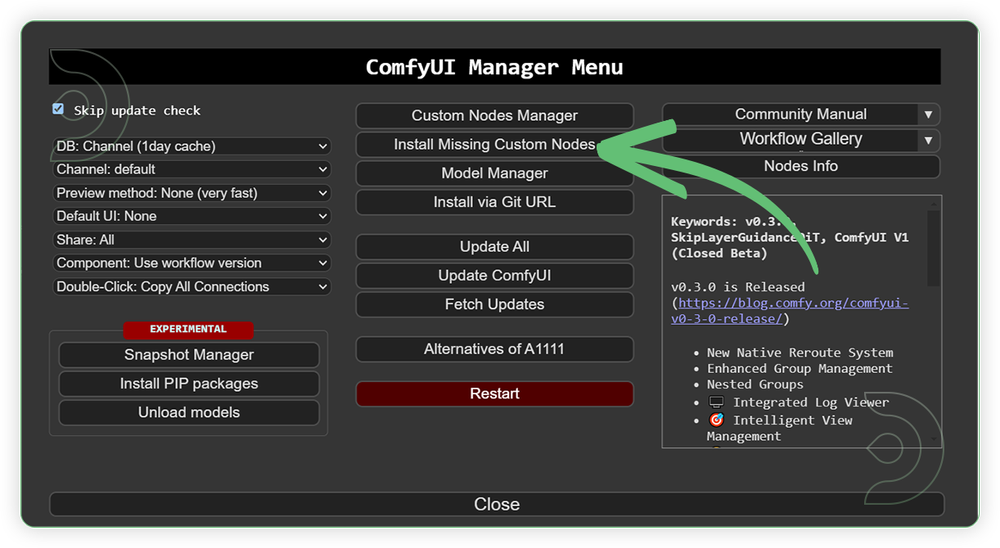
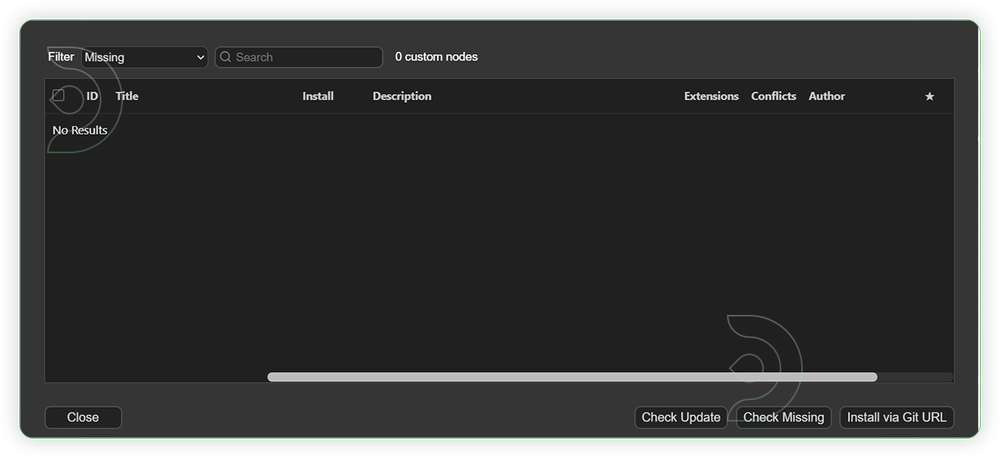
- Check the list below if there's a list of custom nodes that needs to be installed and click the install.
Required Models
For this guide you'll need to download these 1 recommended models.
- Go to ComfyUI Manager > Click Model Manager
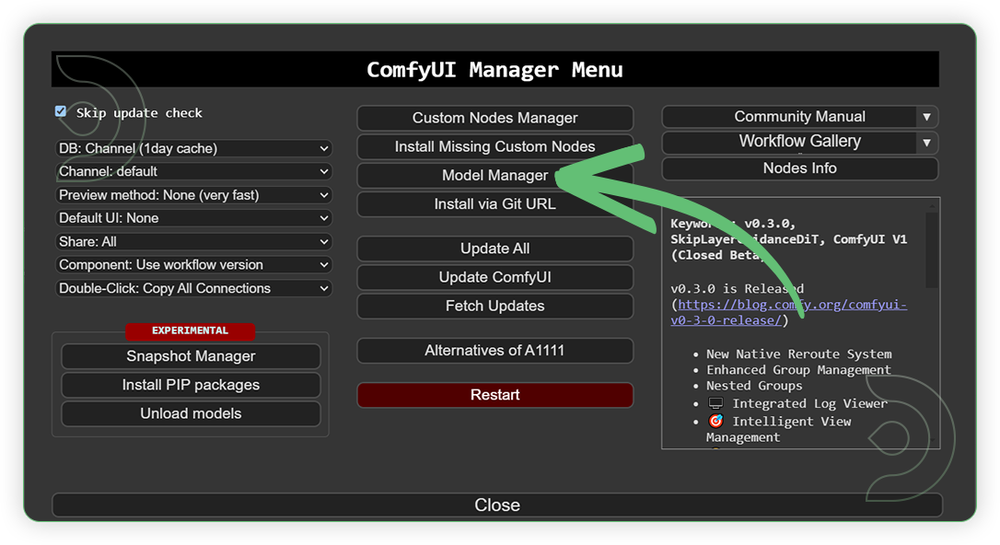
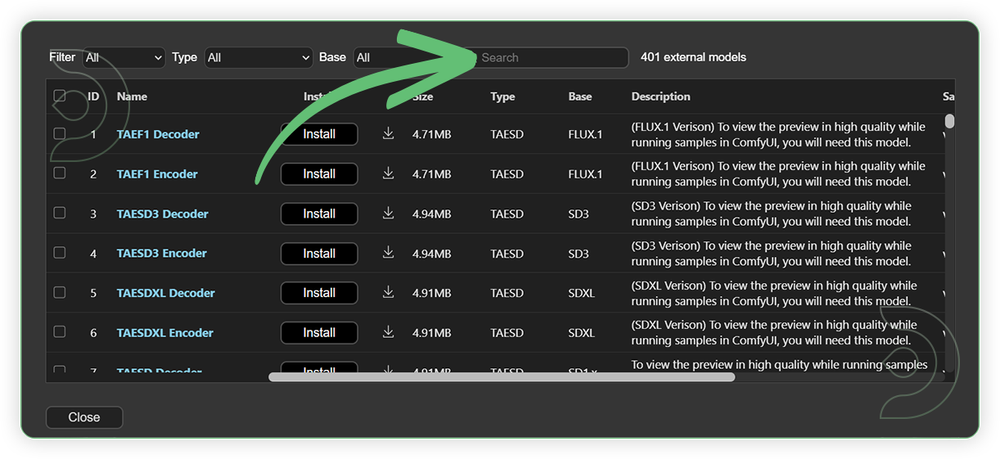
- Search for the models above and when you find the exact model that you're looking for, click install, and make sure to press refresh when you are finished.
If Model Manager doesn't have them: Use direct download links (included with workflow) and upload through ThinkDiffusion MyFiles > Upload URL. Refer our docs for more guidance on this.
You could also use the model path source instead: by pasting the model's link address into ThinkDiffusion MyFiles using upload URL.
| Model Name | Model Link Address | ThinkDiffusion Upload Directory |
|---|---|---|
| wan2.2-rapid-mega-aio-v1.safetensors | .../comfyui/models/checkpoint/ |
Step-by-step Workflow Guide
This workflow was pretty easy to set up and runs well from the default settings. Here are a few steps where you might want to take extra note.
| Steps | Recommended Nodes |
|---|---|
| 1. Set Model Set the exact model as seen on the image. Use only the rapid mega model which can handle a different types of generation mode. |
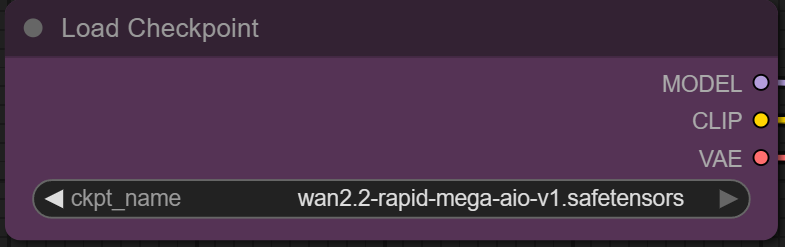 |
| 2. Load Input Load an input image. You can bypass any of these nodes depends of what type of generation mode you are using. |
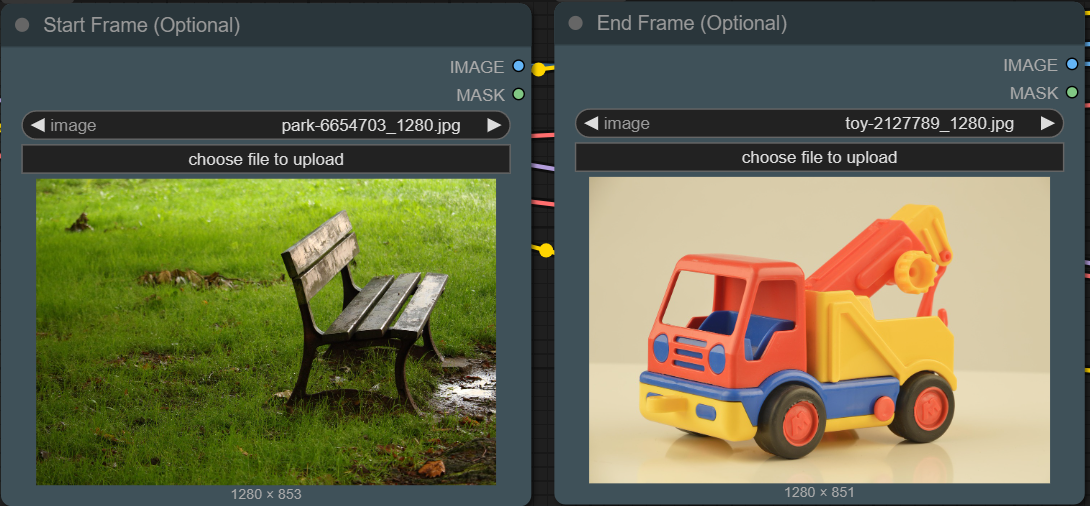 |
| 3. Write Prompt Write the required prompt. It is recommended to write a detailed prompt. |
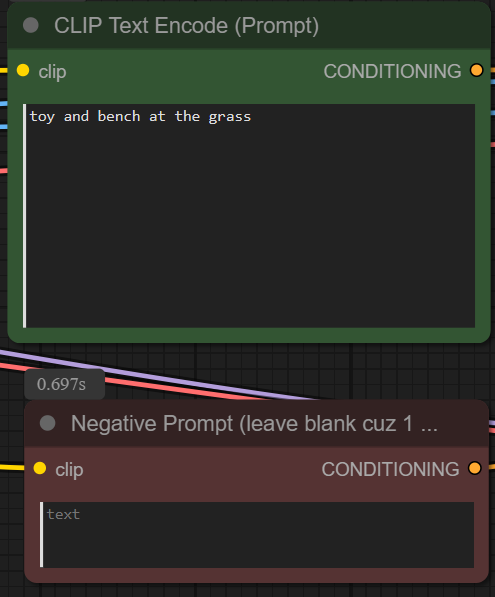 |
| 4. Check Sampling Check the sampling settings. Set it based from the recommended settings of the image. |
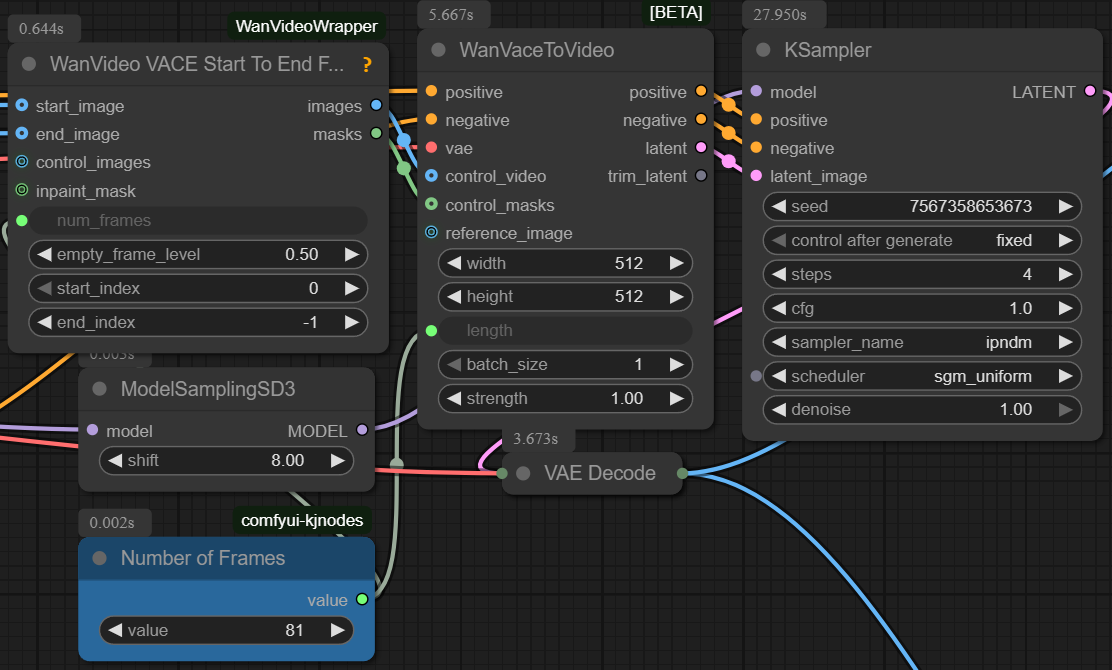 |
| 5. Check Output |
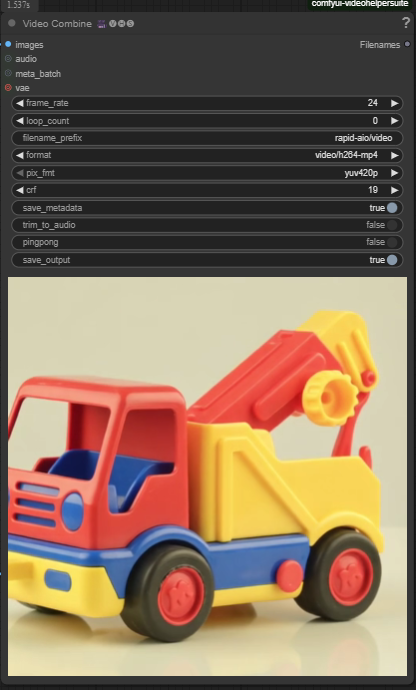 |
T2V mode: Bypass "end frame", "start frame" and the "VACEFirstToLastFrame" node. Set strength to 0 for WanVaceToVideo.
Last Frame mode: Just bypass the "start frame" and keep "end frame". Keep everything else the same as in the picture.
First->Last Frame mode: Use the default workflow of the page.
EXAMPLES
Image to Video
Prompt: An enchanting, lifelike painting comes to life, portraying a cheerful young boy with tousled hair who eagerly greets a smiling girl amid the vibrant greenery of a sunlit park. Their joyful expressions illuminate the scene as sunlight dances across their faces, casting soft shadows beneath swaying trees. Surrounding them, blooming flowers and fluttering butterflies add colorful accents, while distant laughter and a gentle breeze infuse the moment with a sense of carefree happiness.
Text to Video
Prompt: A woman in casual attire strolls across a vast, sunlit expanse of dry land under a brilliant blue sky. Her relaxed outfit flutters gently in the warm breeze as she walks, surrounded by greeny grasses and distant hills. The scene is rendered in a whimsical, soft Ghibli art style, with vibrant colors and a peaceful, dreamy atmosphere.
Last Frame Video
Prompt: Vivid blue butterflies flutter gracefully down onto the soft, emerald-green forest floor, their delicate wings shimmering in the dappled sunlight that filters through the towering canopy above. Around them, a sparse cluster of wild mushrooms rises from the moss, their ivory caps speckled with dew, adding texture and subtle color to the woodland scenery.
First - Last Frame Video
Prompt: A graceful tabby cat with soft golden fur, alert green eyes, and delicate whiskers strolls quietly through the lush, dew-covered grass on a misty morning. With each step, the gentle sunlight illuminates tiny droplets clinging to her paws. Suddenly, she pauses, her gaze fixed on a woven basket nestled among wildflowers—a basket brimming with freshly laid eggs. The scene glows with warm, natural light, highlighting the intricate textures of the cat’s fur, the glistening grass, and the smooth eggshells.
Troubleshooting
Red Nodes: Install missing custom nodes through ComfyUI Manager
Out of Memory: Use smaller expansion factors or switch to Ultra machine
Poor Quality: Check input image resolution and adjust kontext strength
Visible Seams: Lower strength and ensure good prompt description
If you’re having issues with installation or slow hardware, you can try any of these workflows on a more powerful GPU in your browser with ThinkDiffusion.

Member discussion