

Ever found yourself wishing a portrait could actually speak, sharing stories with real movement and emotion? Now, that spark of imagination is within reach—no complicated setups required. With just a bit of creative input, you can watch your favorite images transform into lifelike, expressive talking portraits that surprise, engage, and even make you do a double-take.
What is InfiniteTalk? What are the Key Features?
InfiniteTalk is a powerful audio-driven video generation model designed to create unlimited-length talking avatar videos with exceptionally accurate lip sync, natural head and body movements, and stable facial expressions—all seamlessly aligning to input audio. What sets InfiniteTalk apart from MultiTalk is its enhanced stability, dramatically reduced distortions in hands and body, and superior lip synchronization, making each generated video look more realistic and less prone to awkward or exaggerated motion.
InfiniteTalk is an audio-driven video generation model that creates realistic talking avatar videos from static images or existing videos. It provides:
- Unlimited video length - Generate videos of any duration
- Accurate lip sync - Audio perfectly matches mouth movements
- Natural motion - Realistic head and body movements
- Multi-person support - Handle multiple speakers in one video
- Enhanced stability - Reduced distortions compared to MultiTalk
Perfect for content creators, educators, marketers, and developers who need professional talking avatars.
If you thought only big studios could achieve this kind of realism, prepare to be amazed—InfiniteTalk Video to Video hands you the power to let your portraits do the talking!
Download Workflow
Installation guide
- Download the workflow file
- Open ComfyUI (local or ThinkDiffusion)
- Drag the workflow file into the ComfyUI window
- If you see red nodes, install missing components:
- ComfyUI Manager > Install Missing Custom Nodes
Verified to work on ThinkDiffusion Build: August 21, 2025
ComfyUI v0.3.50 with the use Wan2_1-InfiniTetalk-Single_fp16.safetensors and wan2.1_i2V_480p_14B_fp16.safetensors models
Note: We specify the build date because ComfyUI and custom node versions updated after this date may change the behavior or outputs of the workflow.
Minimum Machine Size: Ultra
Use the specified machine size or higher to ensure it meets the VRAM and performance requirements of the workflow
Custom Nodes
If there are red nodes in the workflow, it means that the workflow lacks the certain required nodes. Install the custom nodes in order for the workflow to work.
- Go to the ComfyUI Manager > Click Install Missing Custom Nodes
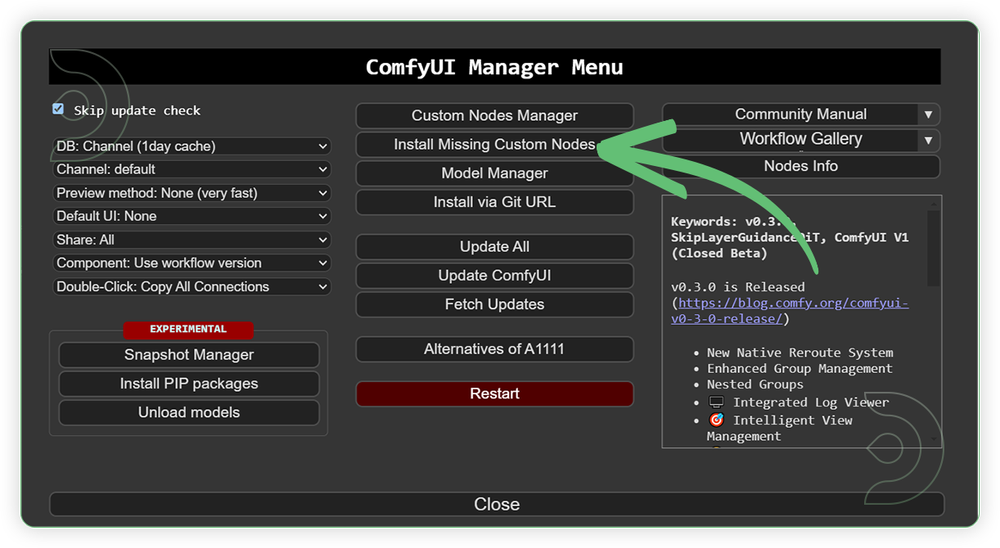
- Check the list below if there's a list of custom nodes that needs to be installed and click the install.
Required Models
For this guide you'll need to download these 6 recommended models.
2. Wan2_1-InfiniTetalk-Single_fp16.safetensors
3. clip_vision_h.safetensors
4. wan2.1_i2V_480p_14B_fp16.safetensors
5. Wan2_1_VAE_bf16.safetensors
6. TencentGameMate/chinese-wav2vec2-base
- Go to ComfyUI Manager > Click Model Manager
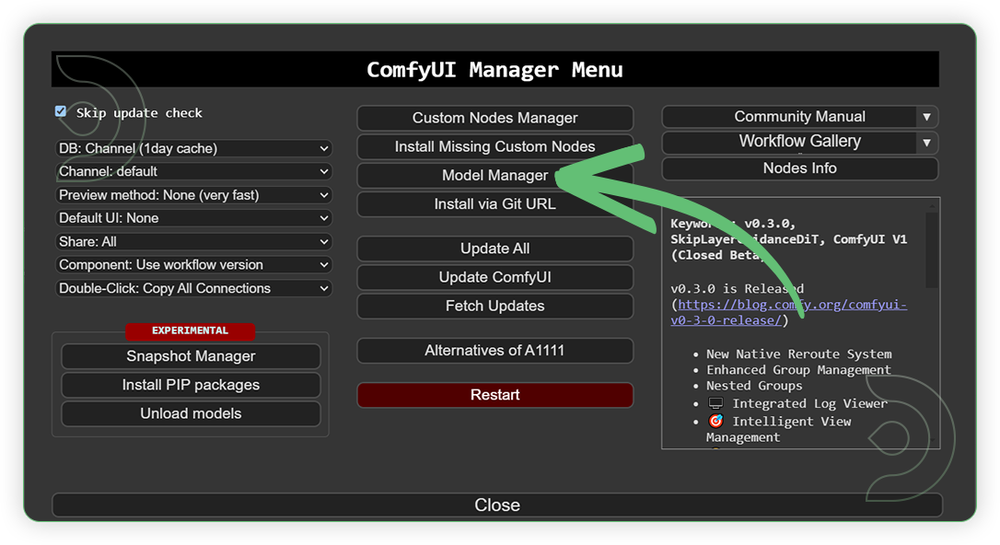
- Search for the models above and when you find the exact model that you're looking for, click install, and make sure to press refresh when you are finished.
If Model Manager doesn't have them: Use direct download links (included with workflow) and upload through ThinkDiffusion MyFiles > Upload URL. Refer our docs for more guidance on this.
You could also use the model path source instead: by pasting the model's link address into ThinkDiffusion MyFiles using upload URL.
| Model Name | Model Link Address | ThinkDiffusion Upload Directory |
|---|---|---|
| lightx2v_I2V_14B_480p_cfg_step_ distill_rank64_bf16.safetensors |
.../comfyui/models/lora/ |
|
| Wan2_1-InfiniTetalk-Single_fp16.safetensors | .../comfyui/models/diffusion_models/ |
|
| clip_vision_h.safetensors | .../comfyui/models/clip_vision/ |
|
| wan2.1_i2V_480p_14B_fp16.safetensors | .../comfyui/models/diffusion_models/ |
|
| Wan2_1_VAE_bf16.safetensors | .../comfyui/models/vae/ |
|
| TencentGameMate/chinese-wav2vec2-base | Auto Download |
Auto Download |
Step-by-step Workflow Guide
This workflow was pretty easy to set up and runs well from the default settings. Here are a few steps where you might want to take extra note.
| Steps | Recommended Nodes |
|---|---|
| 1. Set the Models Set the models as seen on the image. If you got an out of memory, enable the low mem load and use the fp8 version of models. |
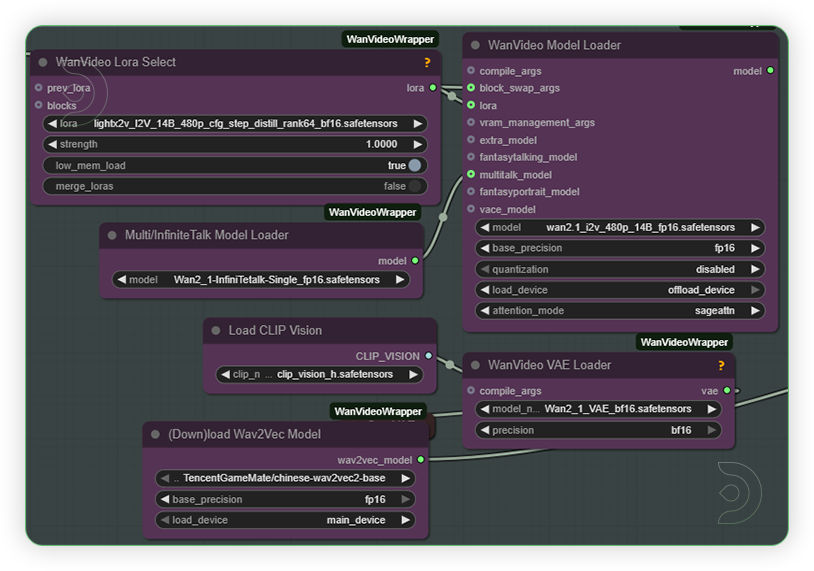 |
| 2. Set the Input Set the input as seen on the image. If you got a higher machine than Ultra then you can set it to the 720p resolution. |
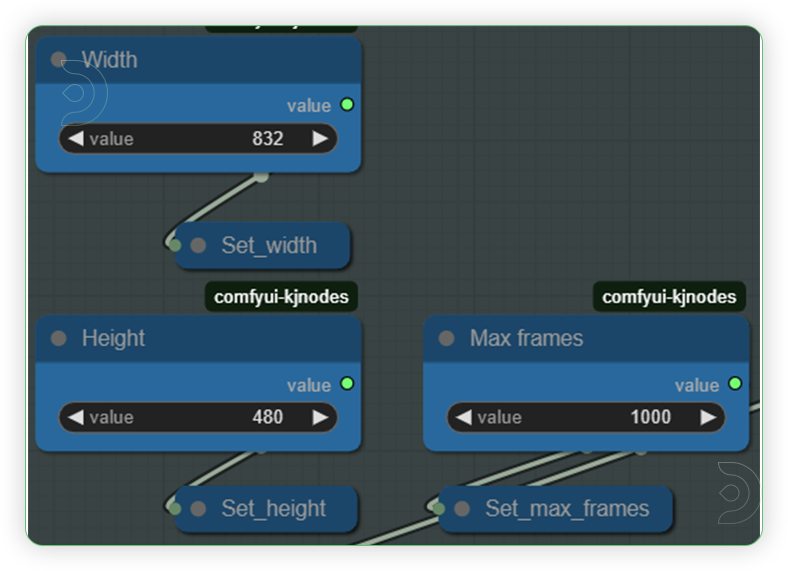 |
| 3. Load the Audio Load an audio file and should be a high quality audio. |
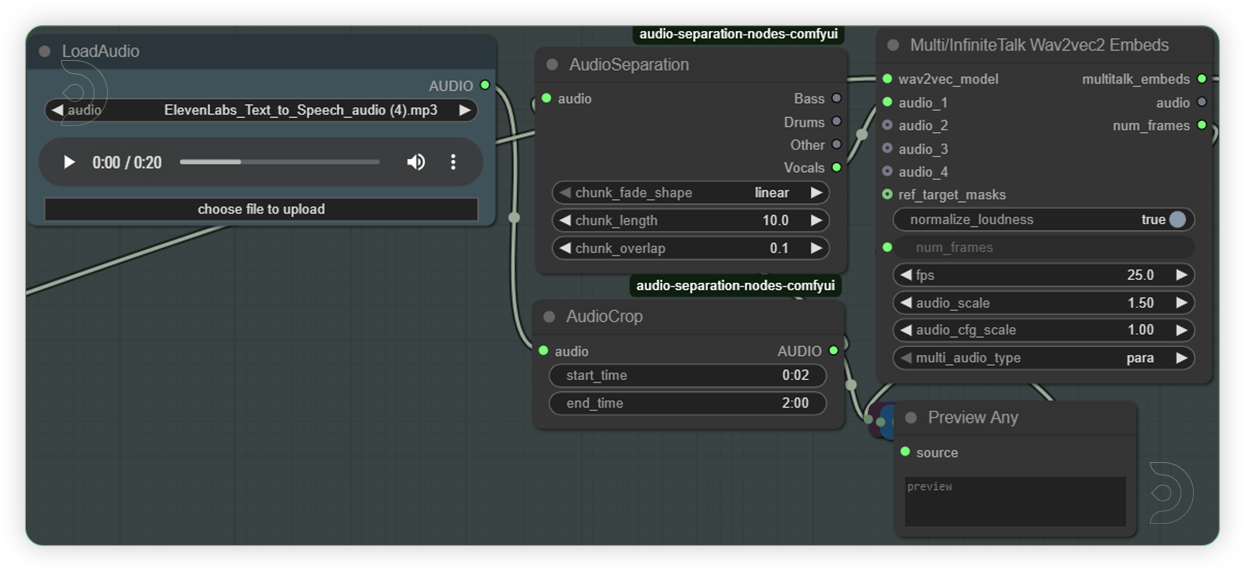 |
| 4. Load the Video Load a video. If the video is vertical then set to vertical input dimesion. Otherwise, use the horizontal settings. |
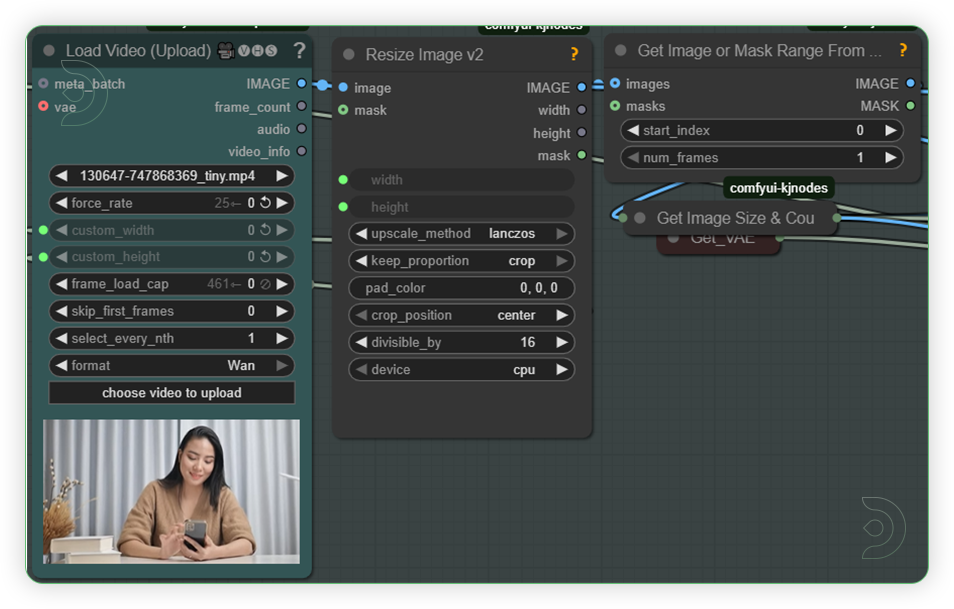 |
| 5. Write the Prompt You can write only a simple prompt. |
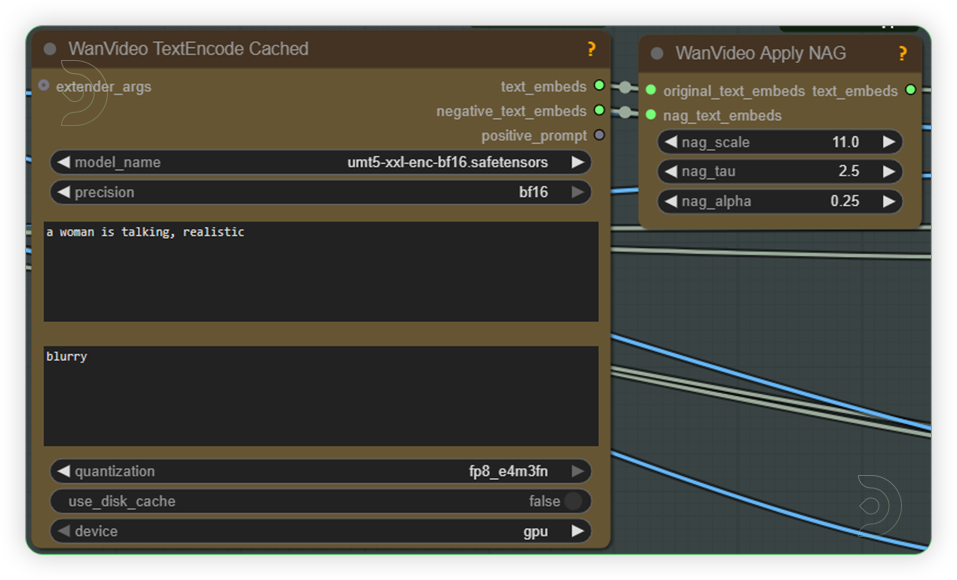 |
| 6. Check the Sampling Set the sampling as seen on the image. |
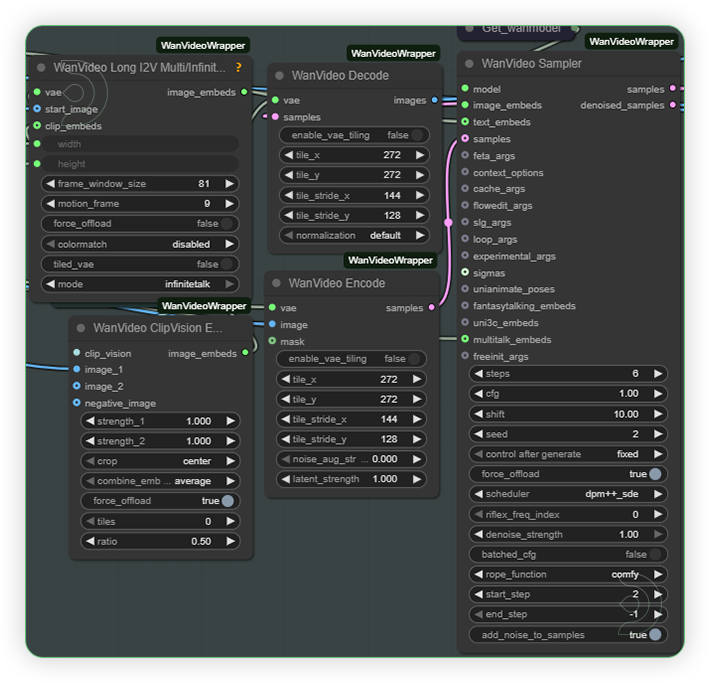 |
| 7. Check the Output |
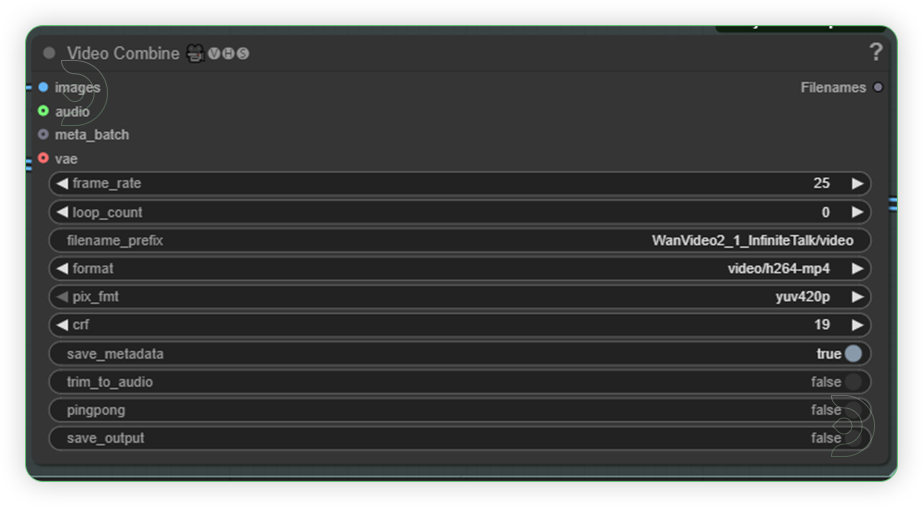 |
Examples
Troubleshooting
Red Nodes: Install missing custom nodes through ComfyUI Manager
Out of Memory: Use smaller expansion factors or switch to Ultra machine
Poor Quality: Check input image resolution and adjust kontext strength
Visible Seams: Lower strength and ensure good prompt description
If you’re having issues with installation or slow hardware, you can try any of these workflows on a more powerful GPU in your browser with ThinkDiffusion.

Member discussion