
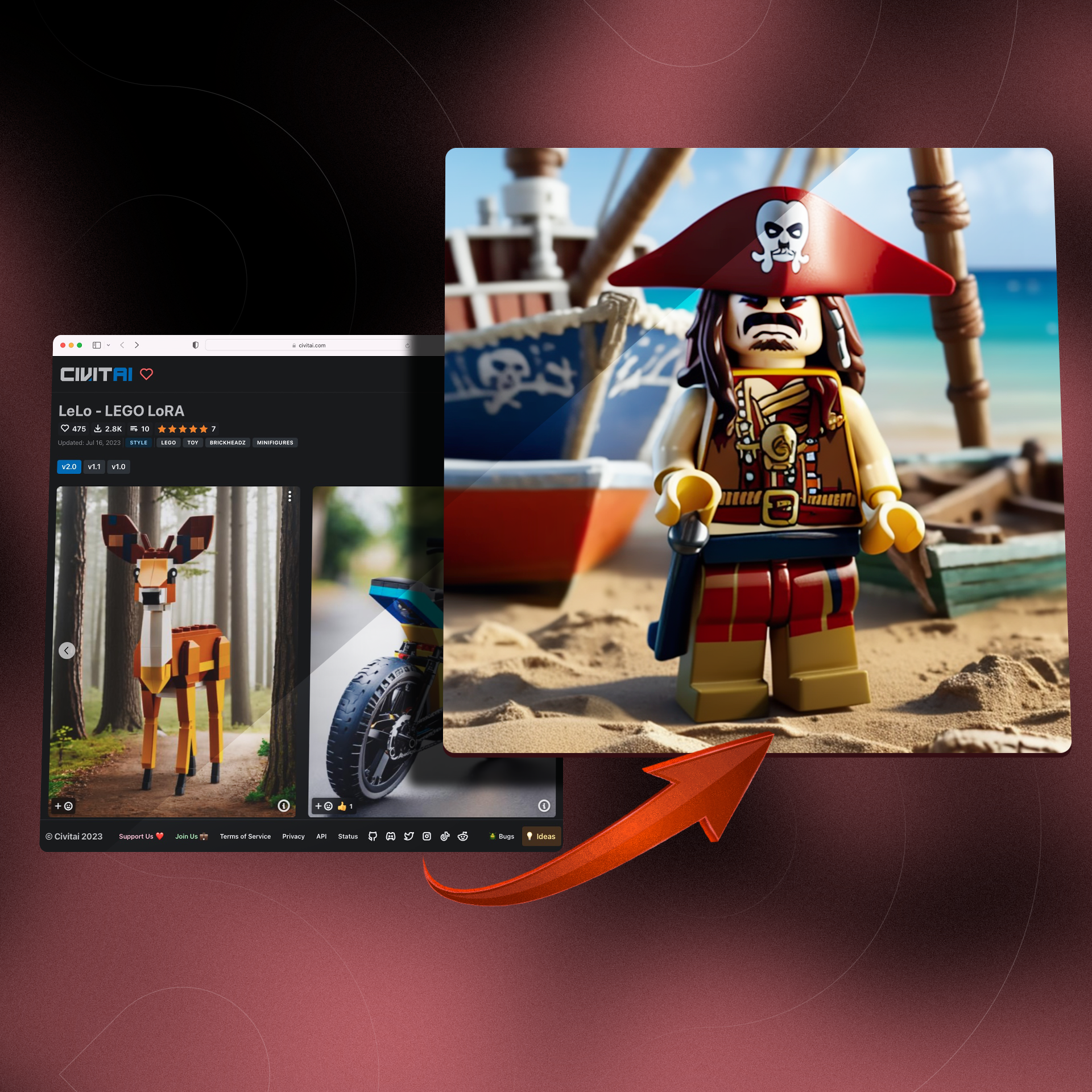
An introduction to LoRA models
LoRA models, known as Small Stable Diffusion models, incorporate minor adjustments into conventional checkpoint models.
Typically, they are sized down by a factor of up to x100 compared to checkpoint models, making them particularly appealing for individuals who possess a vast assortment of models.
This tutorial is tailored for newbies unfamiliar with LoRA models. It will introduce to the concept of LoRA models, their sourcing, and their integration within the AUTOMATIC1111 GUI.




From puppies to paintings, with small LoRA models, you can adapt incredible variety of styles to your artwork
Links to the above LoRA models:
Pixel Art, Ghosts, Barbicore, Cyborg, and Greg Rutkowski-inspired.
Why LoRAs?
LoRA (Low-Rank Adaptation) represents a training technique tailored for refining Stable Diffusion models.
Yet, amidst existing techniques like Dreambooth and textual inversion, what sets LoRA apart?
The significance of LoRA lies in striking a favorable balance between file size and training effectiveness.
Just how big is a LoRA model?
While Dreambooth yields potency, it yields hefty model files (ranging from 2 to 7 GBs). On the other hand, textual inversions are compact (around 100 KBs), but their scope is limited.
LoRA occupies a middle ground. Its file size remains considerably manageable (ranging from 2 to 200 MBs), while maintaining decent training capability.
LoRA's Enhance Existing Checkpoint Models
Similar to textual inversion, a LoRA model can't function in isolation. It necessitates synergy with a model checkpoint file. LoRA brings about stylistic variations by introducing subtle modifications to the corresponding model file.
In addition to this, with the release of SDXL, StabilityAI have confirmed that they expect LoRA's to be the most popular way of enhancing images on top of the SDXL v1.0 base model.
LoRA's can be found at https://civitai.com/ or https://huggingface.co/.
Using LoRA's in Automatic1111
To use LoRA's we need to grab a LORA from either Civitai or Huggingface and then we can upload them to the following folder:
a1111../user_data/a1111/models/Lora/
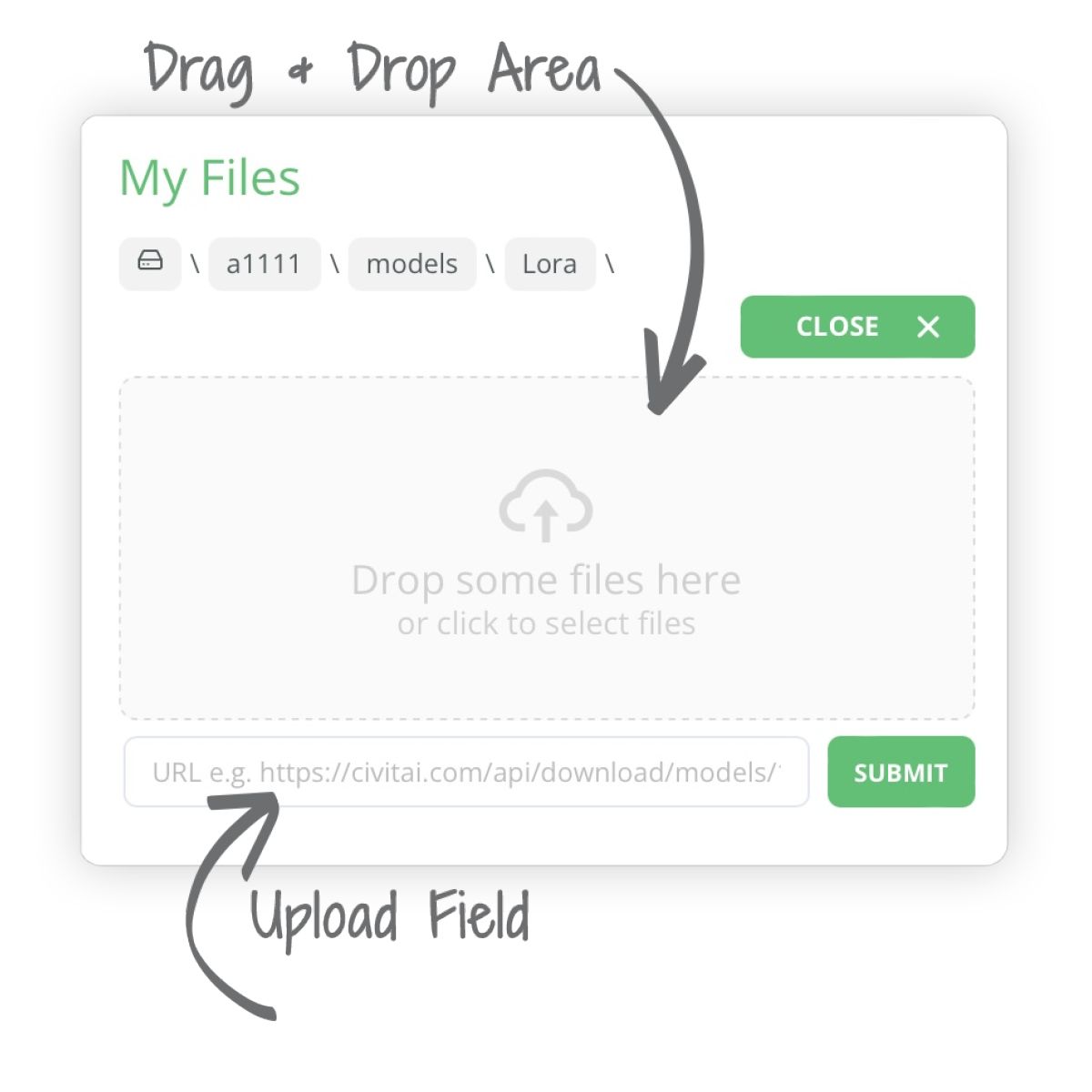
PROTIP 💡:For more info on how to use LoRAs, see our FAQ post here.
Let's use the following Ghibli anime LoRA as an example. Upload this LoRA to the folder mentioned above:
https://civitai.com/models/128832?modelVersionId=141110
Within the txt2Img tab we can now use this LoRA. To view your LoRA's you can:
- Click the 🚨 Show/hide extra networks button
- And select the LoRA sub tab.
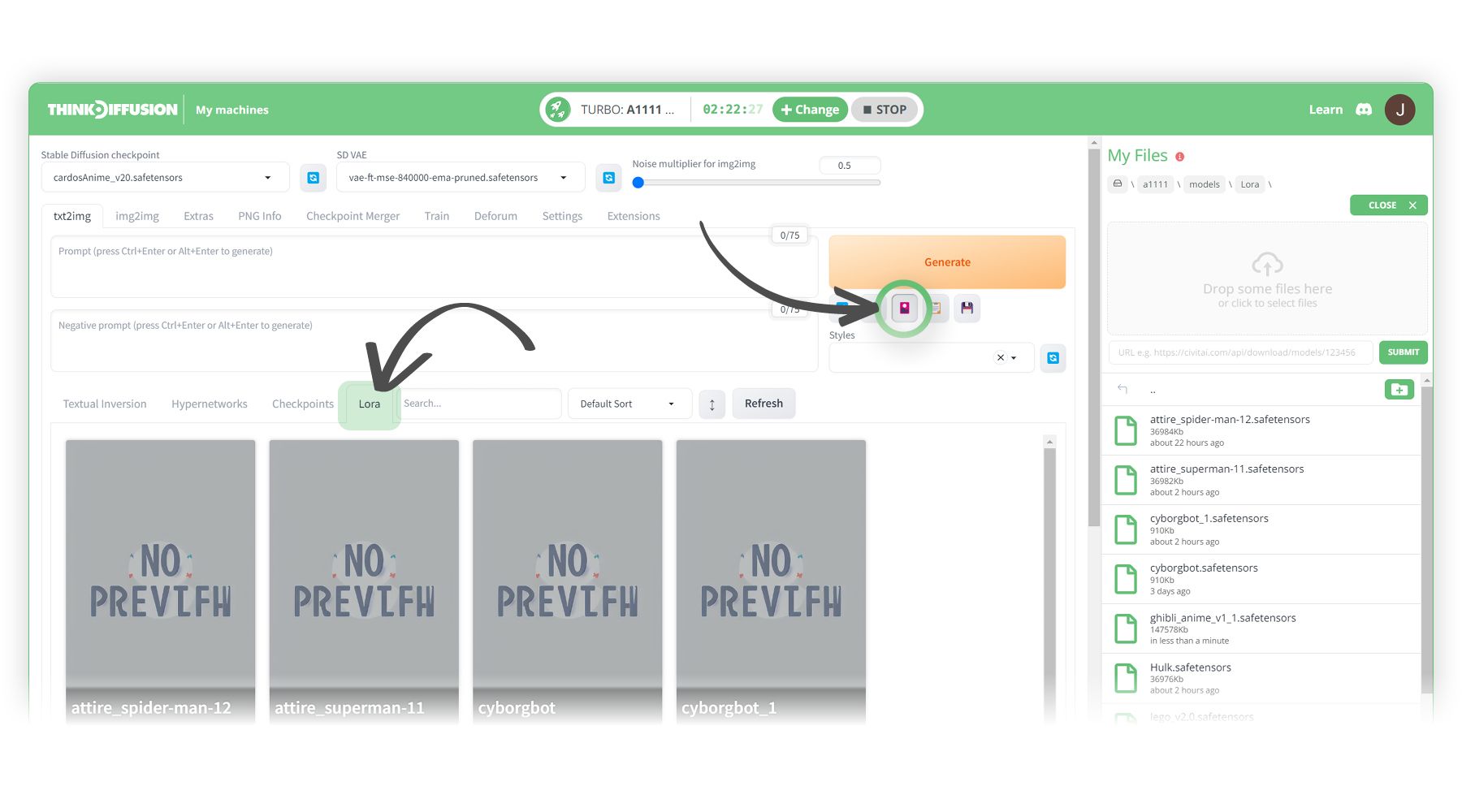
We can then add some prompts and then activate our LoRA:-
- (1) Select CardosAnime as the checkpoint model
- (2) Positive Prompts:
1girl, solo, short hair, blue eyes, ribbon, blue hair, upper body, sky, vest, night, looking up, star (sky), starry sky - (3) Negative prompts: lowres, blurry, low quality
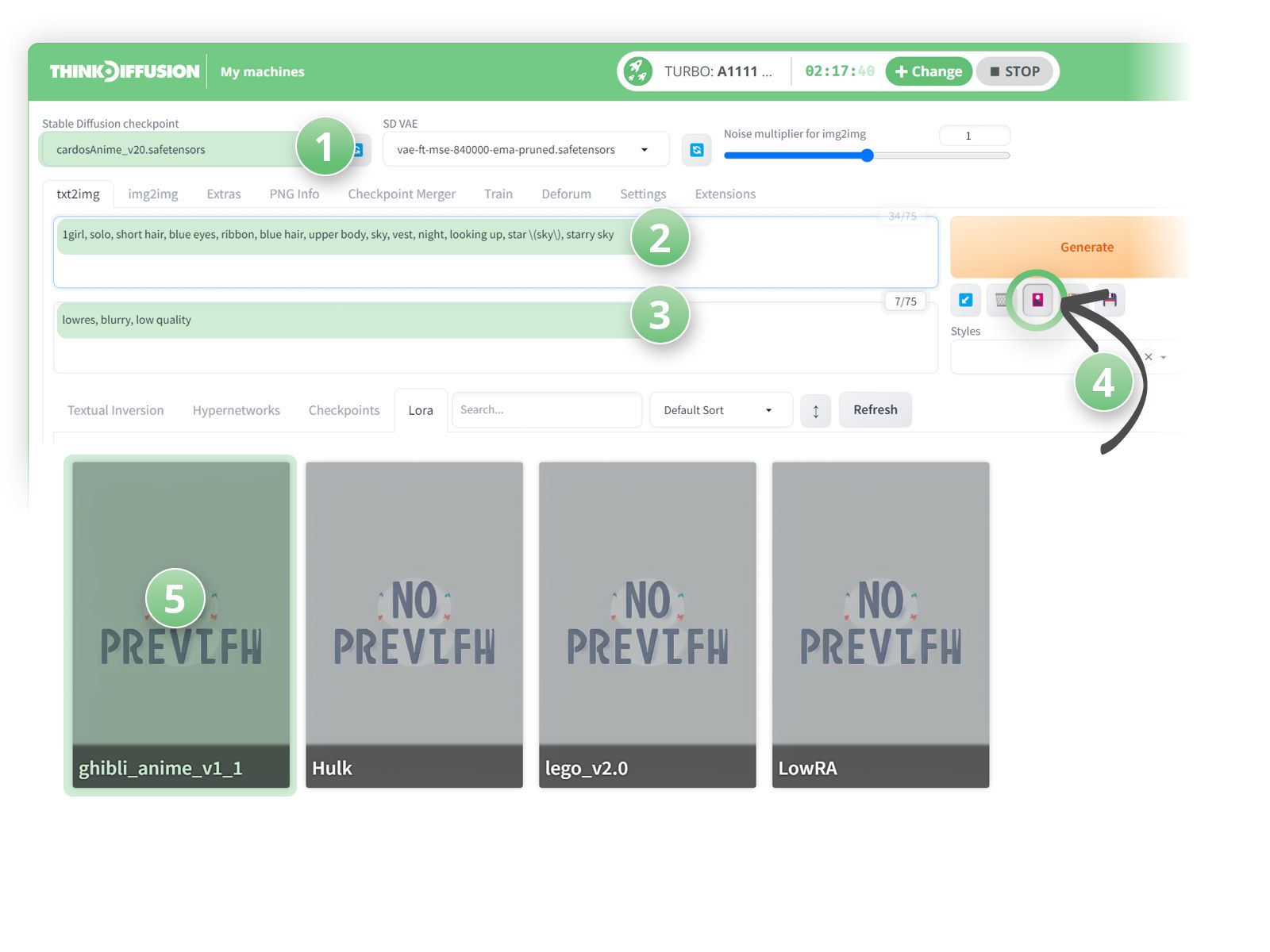
We then need to activate the LoRA by clicking on the LoRA that we want to use.
- (4) Simply click on the 🚨 show/hide extra networks > LoRA subfolder
- (5) And click on the ghibli_anime card
Now our LoRA trigger word is appended <lora:ghibli_anime_v1:1> to the positive prompt as shown below:
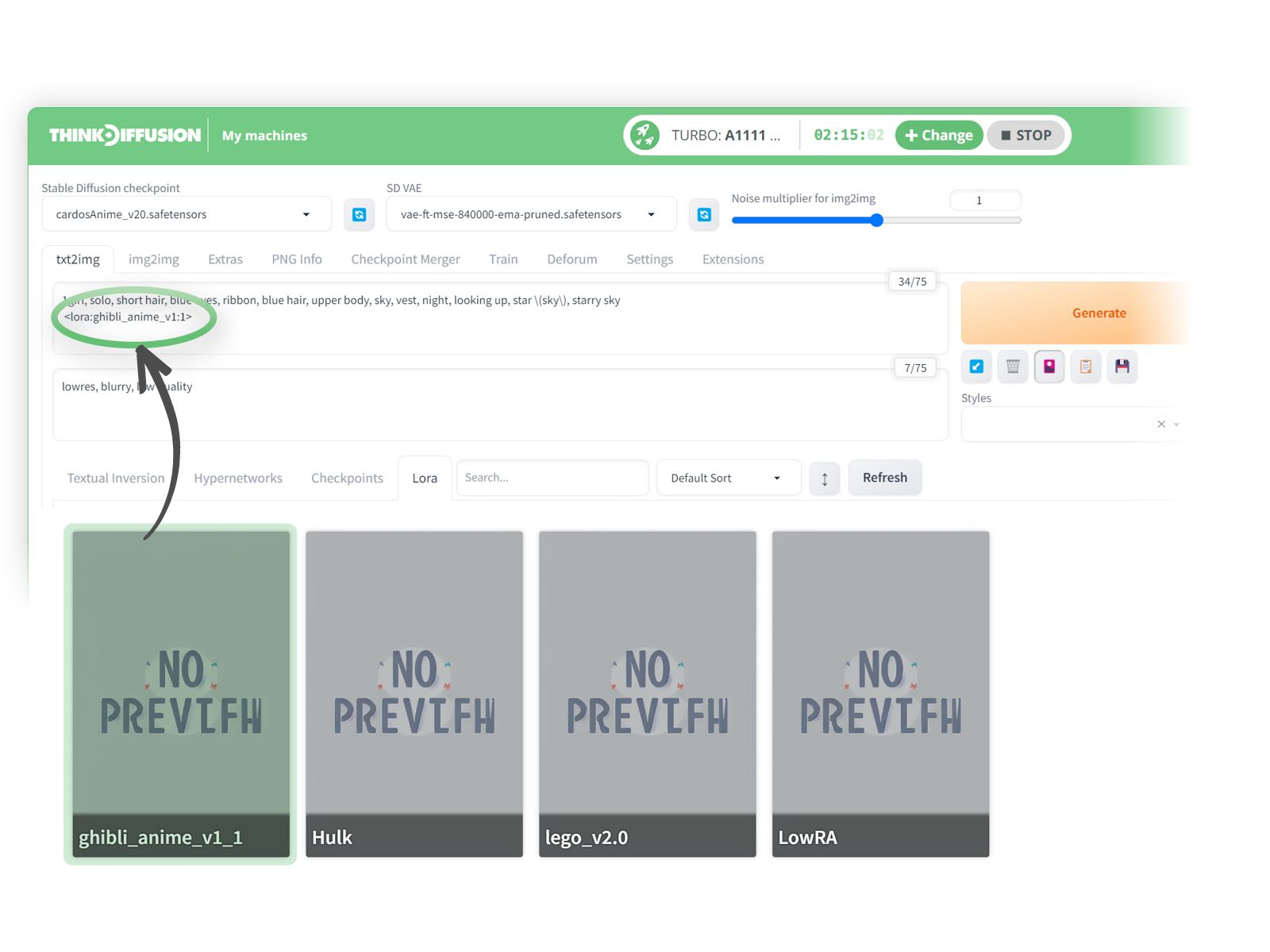
Protip 💡: The value after the colon, which is defaulted to 1 for this particular LoRA is the weighting of the LoRA and can be changed. On Civitai it usually recommends the best weighting within the specific LoRA model page
- Set the sampling steps to 15 and hit Generate!

Now let's play with a few more LoRA's and generate some more images!
The Incredible Hulk
https://civitai.com/models/88753?modelVersionId=94439
- (1) Select RealisticVision as the checkpoint model
- (2) Positive Prompts:
Hulk, photography, trending on artstation, sharp focus, studio photo, intricate details, highly detailed, by greg rutkowski lora:Hulk:0.6 - (3) Negative prompts:
(deformed iris, deformed pupils, semi-realistic, cgi, 3d, render, sketch, cartoon, drawing, anime, mutated hands and fingers:1.4), (deformed, distorted, disfigured:1.3), poorly drawn, bad anatomy, wrong anatomy, extra limb, missing limb, floating limbs, disconnected limbs, mutation, mutated, ugly, disgusting, amputation
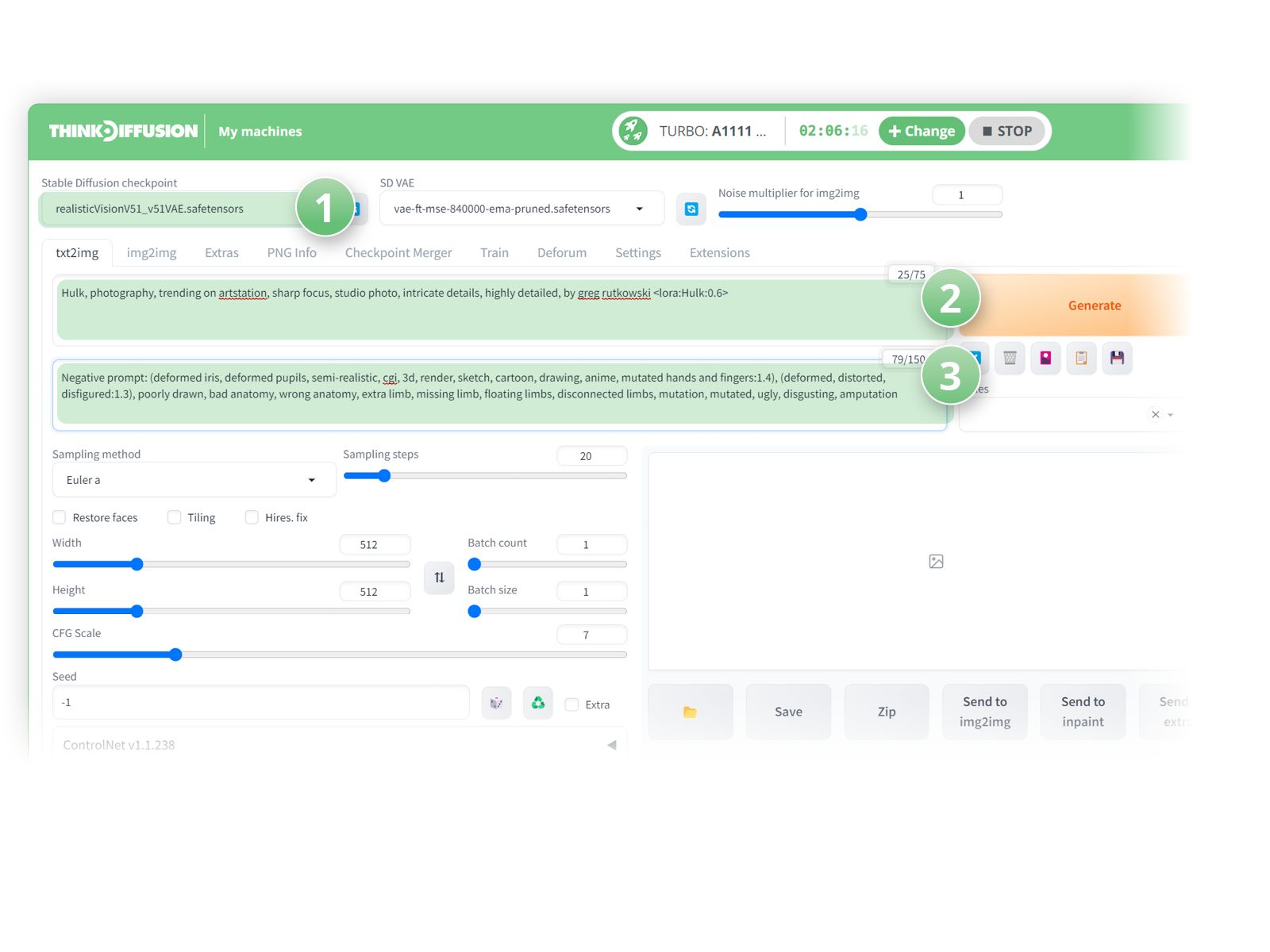
- Hit Generate!

A Lego figure
https://civitai.com/models/92444?modelVersionId=119310
- (1) Select RealisticVision as the checkpoint model
- (2) Positive Prompts:
LEGO MiniFig, Jack Sparrow in the film of Pirates of the Caribbean, standing by a broken boat on beach <lora:lego_v2.0:0.8>, masterpiece, high detail, 8k, high detailed skin, 8k uhd, high quality - (3) Negative prompts:
ugly, disfigured, deformed, worst quality, low quality, logo, text, watermark, username, easynegative, ng_deepnegative_v1_75t, bad-hands-5, bad_artist
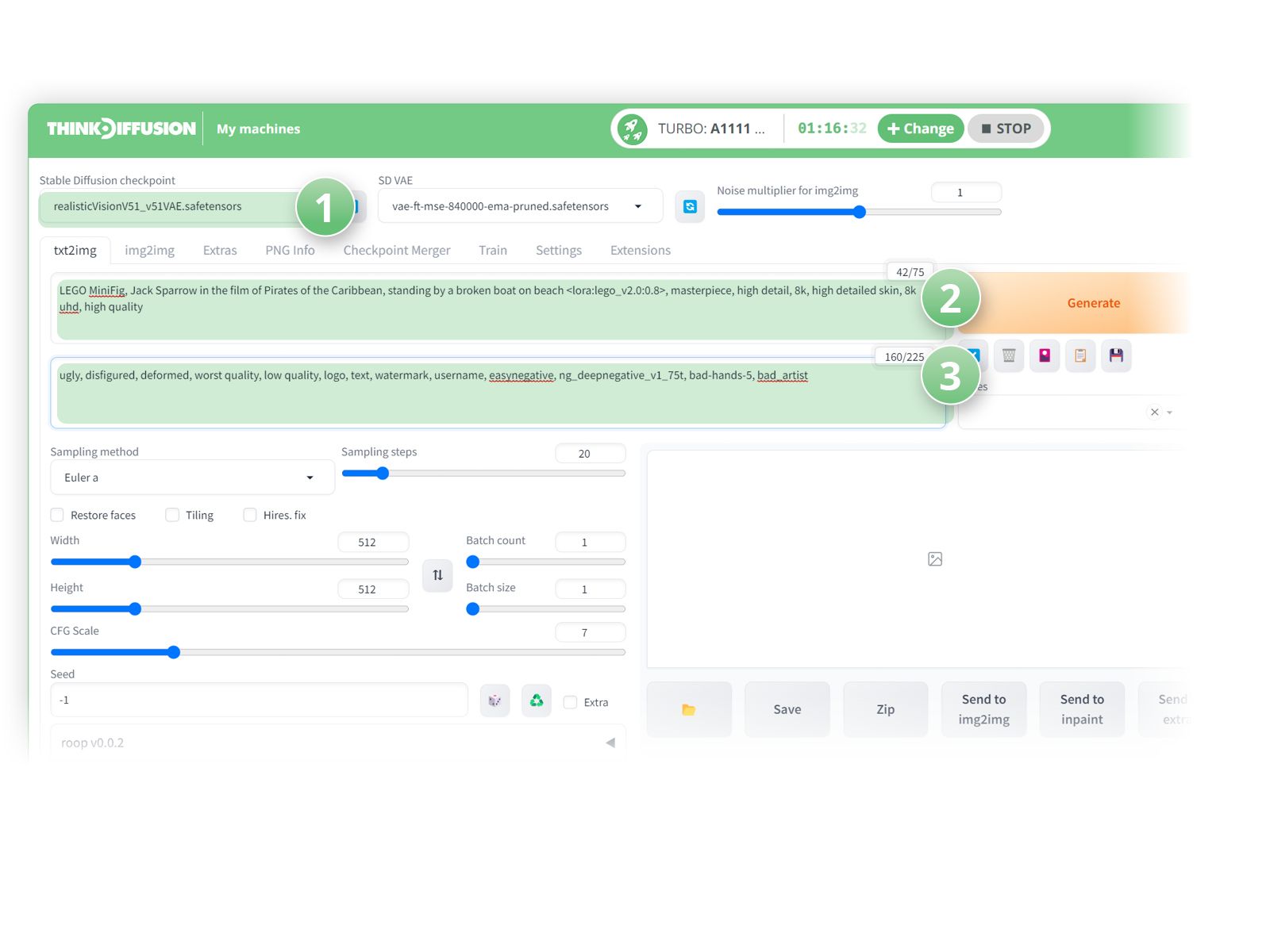
- Hit Generate!

A mechanical cat
https://civitai.com/models/99437?modelVersionId=106415
- (1) Select RealisticVision as the checkpoint model
- (2) Positive Prompts:
sleek black stealth mechanical cat,car, cyberpunk city in background, lora:Mechanicalcat:0.7 - (3) Negative prompts:
(worst quality:2), (low quality:2), (normal quality:1.8), lowres, ((monochrome)), ((grayscale)),sketch,ugly,morbid, deformed,logo,text, bad anatomy,bad proportions
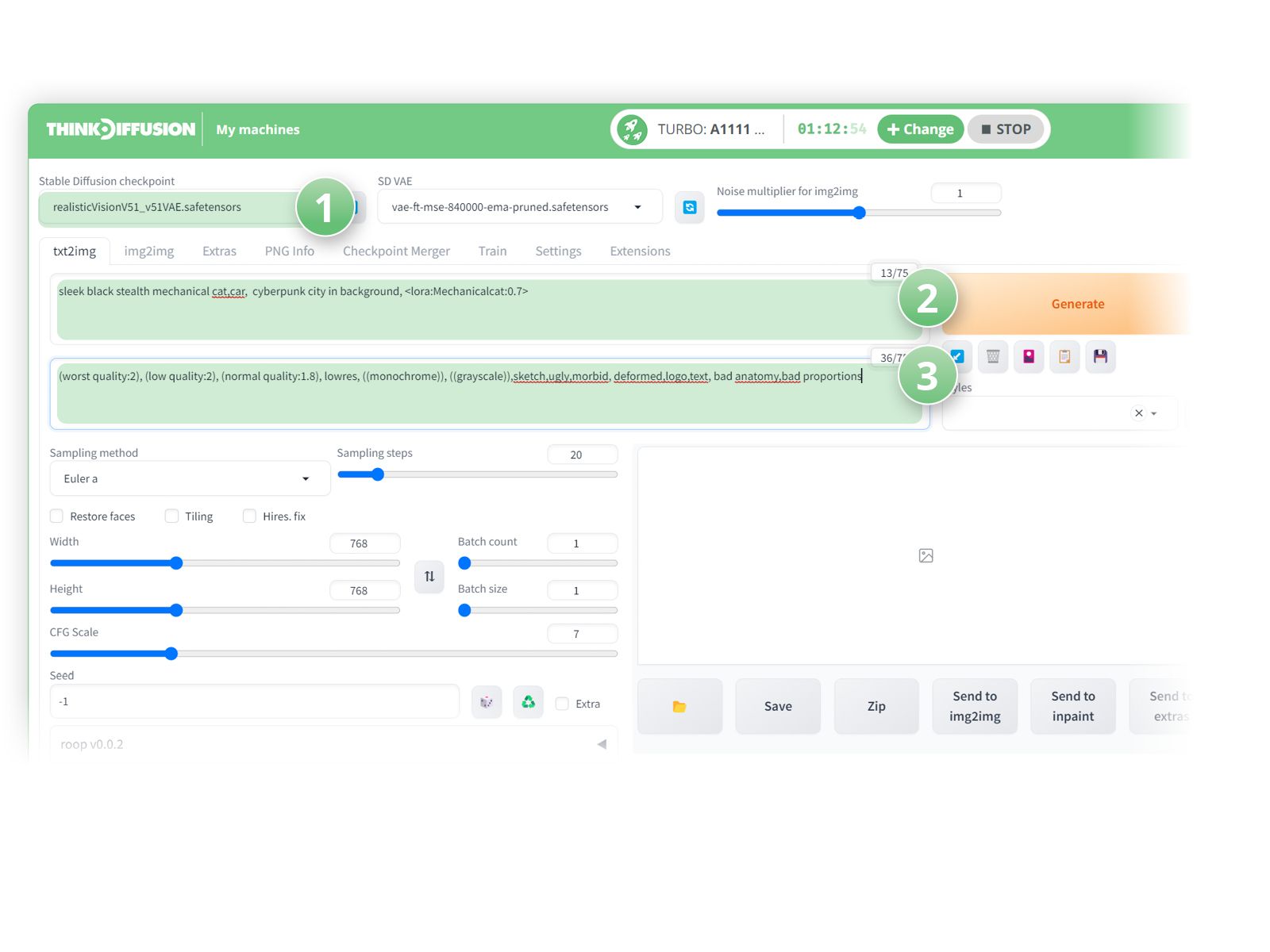
- Hit Generate!

There are hundreds of LoRA's available, check out what's out there to add those extra details to your images!
Any of our workflows can run on a local version of SD but if you’re having issues with installation or slow hardware, you can try any of these workflows on a more powerful GPU in your browser with ThinkDiffusion.
If you’d like to have more control over your character's poses, check out my post to using OpenPose here. Let me know what you're making with LoRAs, and enjoy changing up your styles!

Member discussion