

Prompt: A solitary man walks alongside his three camels across the expansive, sun-soaked desert, their pace steady under the relentless sun. The camels' hooves leave a series of rhythmic imprints in the golden sands as their elongated shadows stretch far into the distance, weaving patterns that dance toward the distant horizon.
The recently released Wan 2.1 is a groundbreaking open-source AI video model. Renowned for its ability to exceed the performance of other open-source models like Hunyuan and LTX, as well as numerous commercial alternatives, Wan 2.1 delivers truly incredible text2video and image2video generations with little effort. While it sacrifices generation speed compared to competitors, the quality of its video production is exceptional.
So, ready to see your ideas come to life with Wan?
What Makes Wan Unique
Prompt: In an old, cherished photograph, a sister beams brightly as she carries her younger brother, who wears a cozy hoodie, both capturing the warmth and joy of their sibling bond. Their smiles illuminate the image, exuding a timeless happiness that echoes fond memories of their shared moments.
Wan Image to Video Architecture
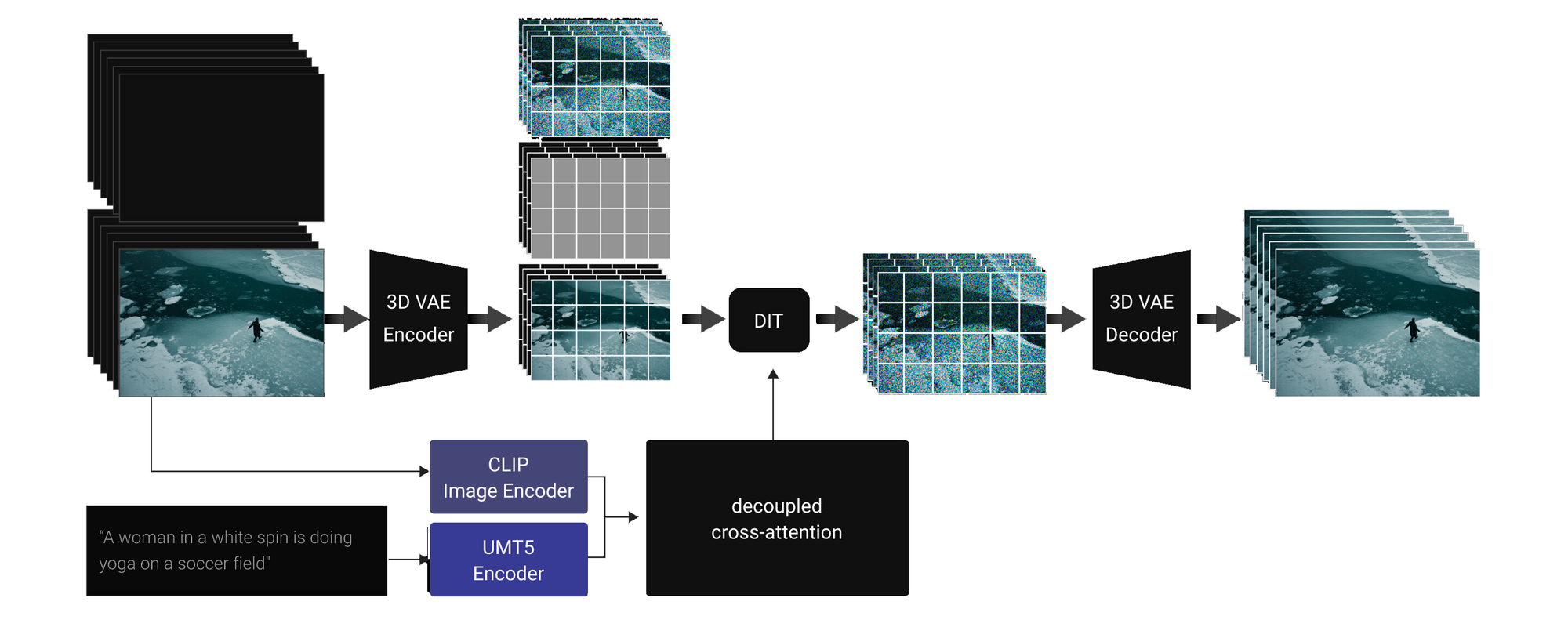
The Image-to-Video (I2V) task changes a picture into a video using a control prompt. It begins with an image, and a mask decides which frames to keep or generate, while a 3D Variational Autoencoder (VAE) compresses the images. This data goes into the DiT model, which has an extra layer because it uses more channels. A CLIP image encoder gets features from the image to provide context, added using cross-attention. After it has been generated the VAE again decodes the images back from the latent space into images we can see.
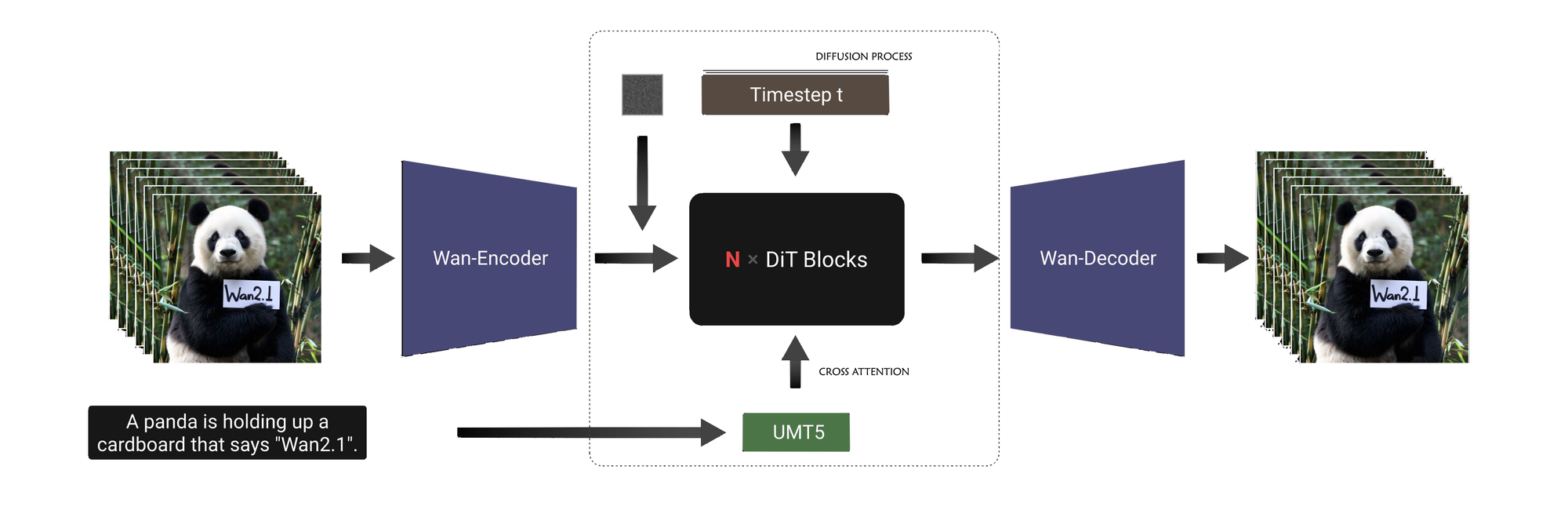
Diffusion Process
Prompt: Under the tranquil canopy of a blue starlit night, an anime scene unfolds where the silhouettes of a sweet couple stand closely together, framed by the gentle rustle of windy grass. The sparkling stars above cast a magical glow, enveloping the pair in a serene moment of connection and wonder.
How to run Wan 2.1 in ComfyUI for ImagetoVideo Generation
Installation guide
Verified to work on ThinkDiffusion Build: June 27, 2025
ComfyUI v0.3.47 with
Wan2_1-I2V-14B-480P_fp8_e4m3fn.safetensors support.
Why do we specify the build date? ComfyUI and custom node versions that are part of this workflow that are updated after this date may change the behavior or outputs of the workflow.
Minimum Machine Size: Ultra
Use the specified machine size or higher to ensure it meets the VRAM and performance requirements of the workflow
Custom Nodes
If there are red nodes in the workflow, it means that the workflow lacks the certain required nodes. Install the custom nodes in order for the workflow to work.
- Go to ComfyUI Manager > Click Install Missing Custom Nodes
- Check the list below if there's a list of custom nodes that needs to be installed and click the install.
Models
For this guide you'll need 4 recommended models to be downloaded.
2. umt5_xxl_fp16.safetensors
3. wan_2.1_vae.safetensors
4. clip_vision_h.safetensors
Models can be downloaded from Comfy.Org or the model manager.
- Go to ComfyUI Manager > Click Model Manager
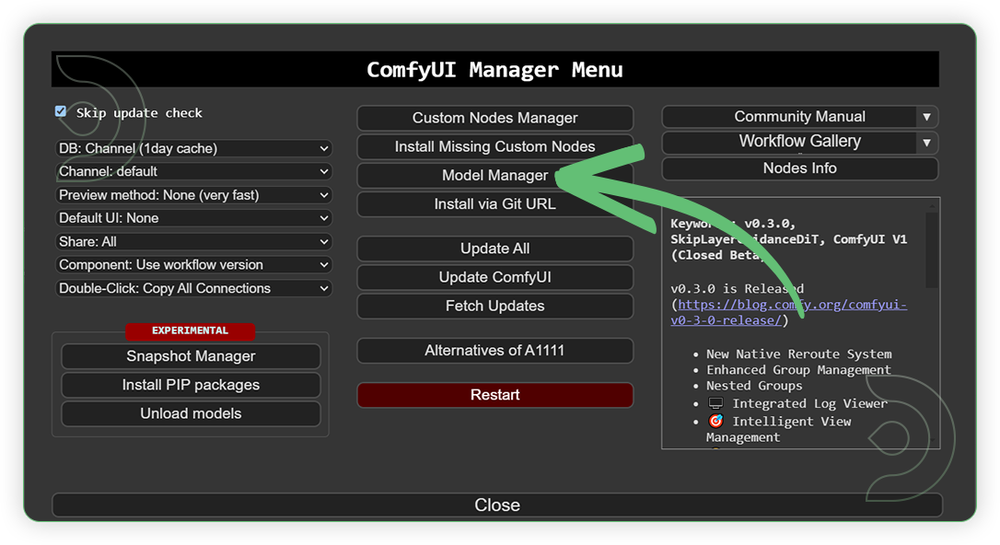
- Search for the models above and when you find the exact model that you're looking for, click install and make sure to press refresh when you are finished.
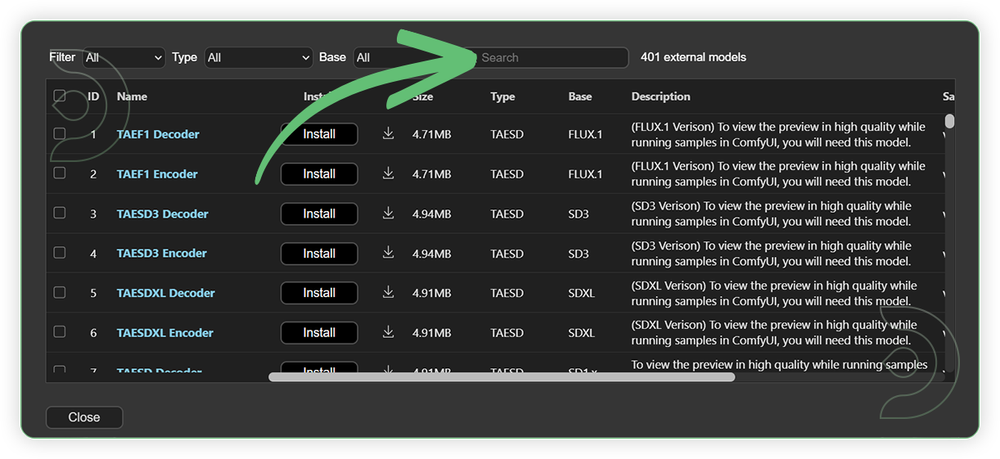
Model Path Source
Some of my models may not be available in the model manager. Use the model path source instead if you prefer to install the models using model's link address and paste into ThinkDiffusion MyFiles using upload URL.
| Model Name | Model Link Address | ThinkDiffusion Upload Directory |
|---|---|---|
Wan2_1-I2V-14B-480P_fp8_e4m3fn.safetensors |
.../comfyui/models/diffusion_models/ |
|
| umt5_xxl_fp16.safetensors | .../comfyui/models/text_encoders/ |
|
| wan_2.1_vae.safetensors | .../comfyui/models/vae/ |
|
| clip_vision_h.safetensors | .../comfyui/models/clip_vision/ |
Step-by-step Workflow Guide
This workflow was pretty easy to set up and runs well from the default settings. Here are a few steps where you might want to take extra note.
| Steps | Recommended Nodes |
|---|---|
| 1. Load Image Load an image |
 |
| 2. Set Size When resizing the image, make that sure the resolution does not exceed 1280 x 720 as that will increase generation time drastically. Reduce to speed up generation time. Enable keep proportion to keep the aspect ratio of your input image |
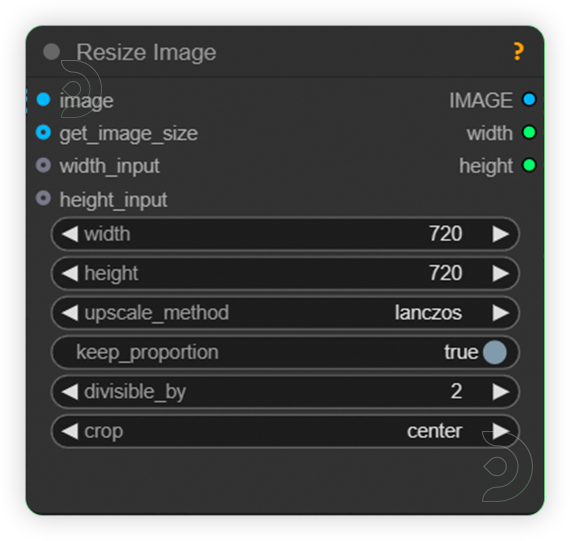 |
| 3. Set Models Set the models as seen on the image. It should be the same files from the official source repo https://huggingface.co/Comfy-Org/Wan2.1ComfyUIrepackaged |
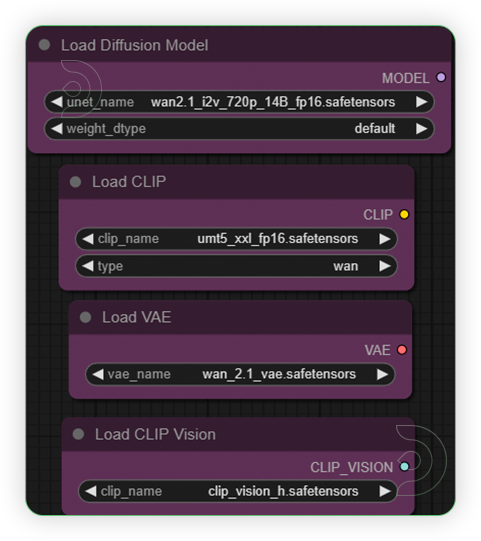 |
| 4. Write a Prompt You can write any prompt you want. Wan2.1 has no limitation |
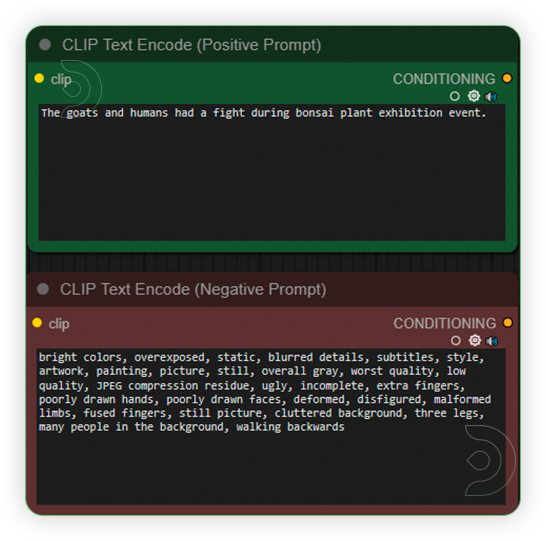 |
| 5. Check the Generation Settings We recommend unipc for sampler and simple for scheduler The length is 16 frames per second +1. So 5 seconds would be 81 frames |
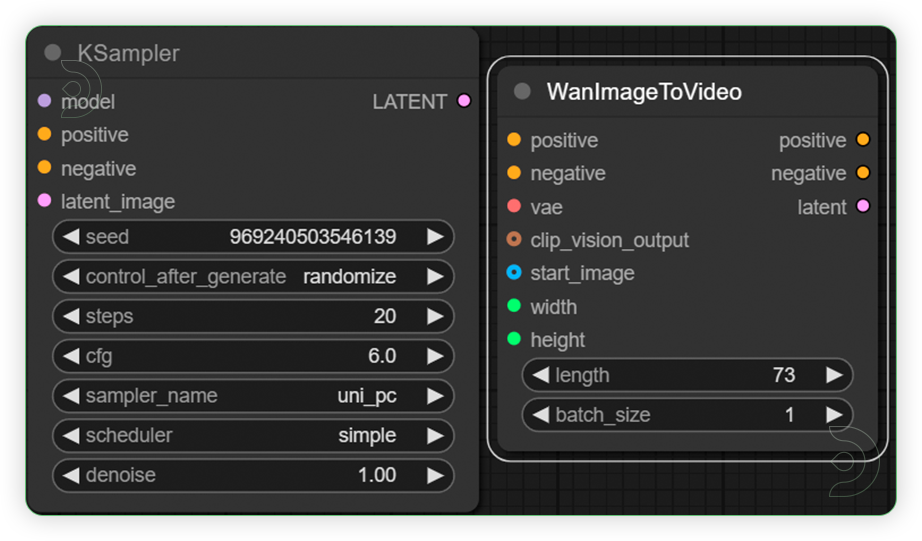 |
| 6. Check the Generated Video |
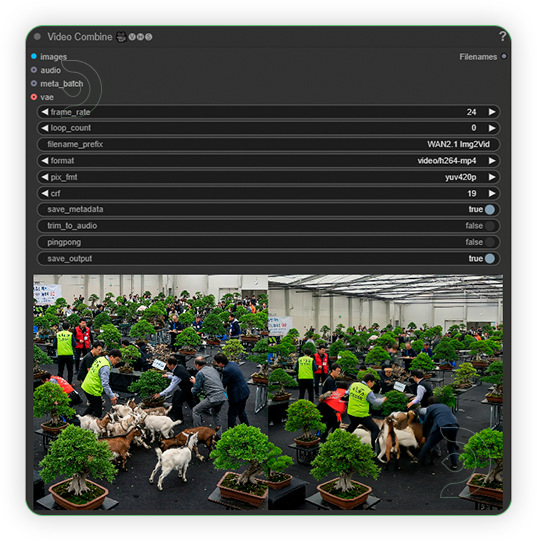 |
Examples
The examples below displays different ranges of tasks such as portrait video, complex motions, animation, physical simulation, cinematic quality and camera control.
-20 steps
-6 cfg
-uni_pc sampler
-simple scheduler
Portrait
Prompt: A professional man sits confidently on a vibrant yellow bench, his posture relaxed yet assertive as he faces the camera. His expression is animated and focused, with a lively conversation unfolding. Gesturing occasionally, his eyes convey enthusiasm and his smile hints at the depth of engagement in the dialogue, all set against the backdrop of a bustling urban park.
Complex Motions
Prompt: Five women, each elegantly dressed in white, command the stage as they dance in perfect harmony, their movements uniform and synchronous, creating a mesmerizing spectacle for the audience.
Animation
Prompt: A pretty anime girl sits atop a city building, silhouetted against the sprawling urban landscape. Her headphones rest comfortably over her ears as she sings softly, her melodic voice mingling with the distant hum of city life, while a gentle breeze ruffles her hair under the twinkling city lights.
Physical Simulation
Prompt: A cat stands in the bustling kitchen, adorably mimicking a real-life chef. With a tiny apron tied snugly around its waist and a little chef's hat perched atop its head, it playfully swats at the flour with its paw, causing a small cloud to rise. Its tail flicks with concentration as it carefully paws at the rolling pin, determined to bake a culinary masterpiece amidst the delicious aromas wafting through the air.
Cinematic Quality
Prompt: Ghost Rider races through the night's shadows on his blazing motorcycle, roaring down the city streets with supernatural speed. The tires, engulfed in flames, leave a trail of fiery light as they sear the pavement, creating a mesmerizing spectacle against the backdrop of twinkling city lights and towering skyscrapers.
Camera Control
Prompt: A drone glides effortlessly through the sky, capturing an aerial view that highlights the vivid structures of houses below. As it flies forward, the rooftops form an intricate tapestry, showcasing a colorful array of architecture nestled within the landscape, painting a vibrant portrait of the community from above.
If you’re having issues with installation or slow hardware, you can try any of these workflows on a more powerful GPU in your browser with ThinkDiffusion.
If you enjoy ComfyUI and you want to test out creating awesome images, then feel free to check out this OmniGen tutorial here. And have fun out there with your videos!
If you're having issues with workflow and visit us here at Discord #Help Desk or you may opt to email us at support@thinkdiffusion.com

Here are some more image to video tutorials you might like:


Member discussion